やり方はここに書いてあります。
大まかな手順です。
ComfyUIでワークフローを作る
ComfyUIでワークフローを作ります。これはデフォルトのワークフローのままでも動くので、ComfyUIに詳しくなくても大丈夫です。
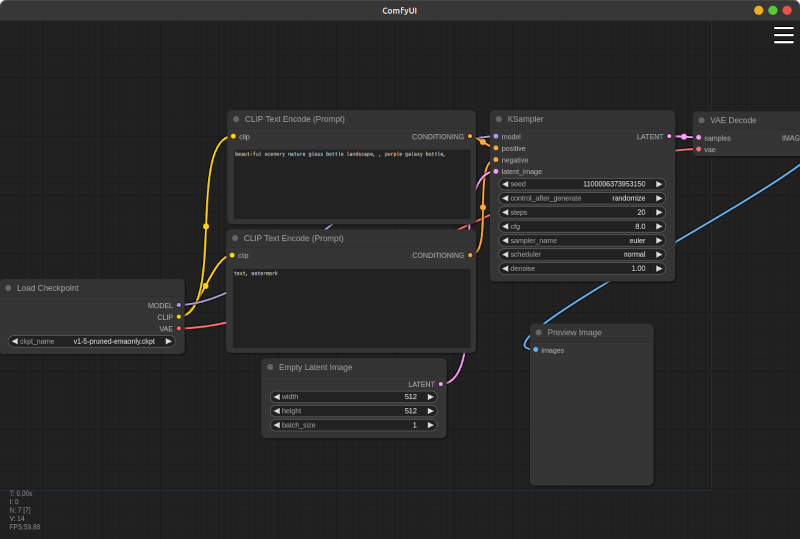
ワークフローをファイルに書き出す
ワークフローの準備ができたら、設定画面で「Enable Dev mode Options」をオンにし、メニューから「Save (API Format)」を選んでワークフローを workflow_api.json ファイルを書き出します。
Open WebUIの画像設定
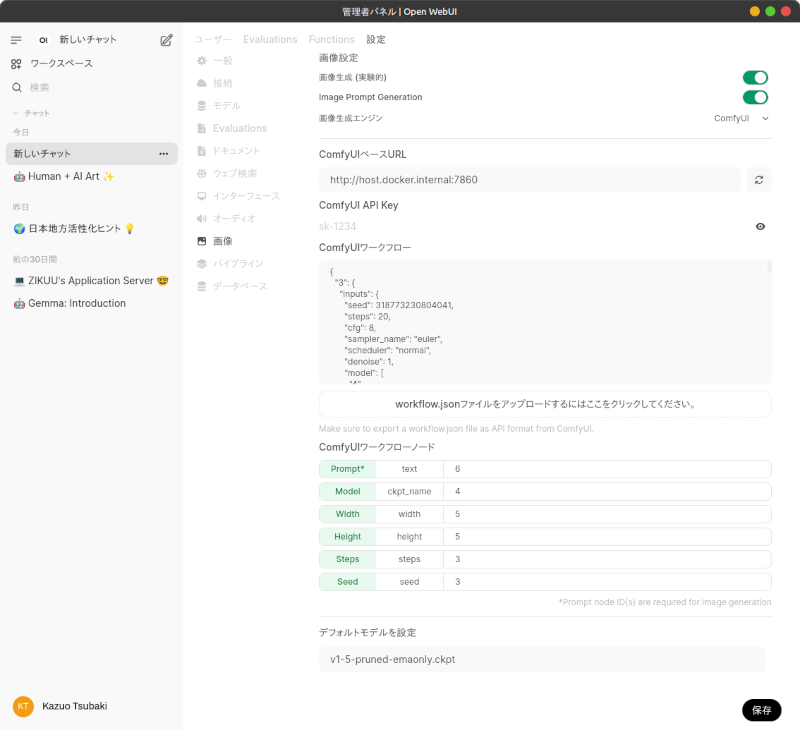
次にOpen WebUIの画像設定を行います。
「画像生成(実験的)」をオンに、「Image Prompt Generation」をオンに、「画像生成エンジン」をComfyUIにし、「ComfyUIベースURL」をComfyUIのURLに設定します。
「workflow.jsonファイルをアップロードするにはここをクリックしてください。」ボタンを押して、先程ComfyUIで書き出したworkflow_api.jsonを読み込みます。
読み込んだworkflow_api.jsonファイルから、ワークフローのノードIDを見つけて、「ComfyUIワークフローノード」の3列目をそのノードIDで埋めます。
最後に「デフォルトモデルを設定」でComfyUIで使用するモデルを選択し、「保存」ボタンを押して設定を保存します。
実行
これで実行の準備ができました。
早速、実行です。
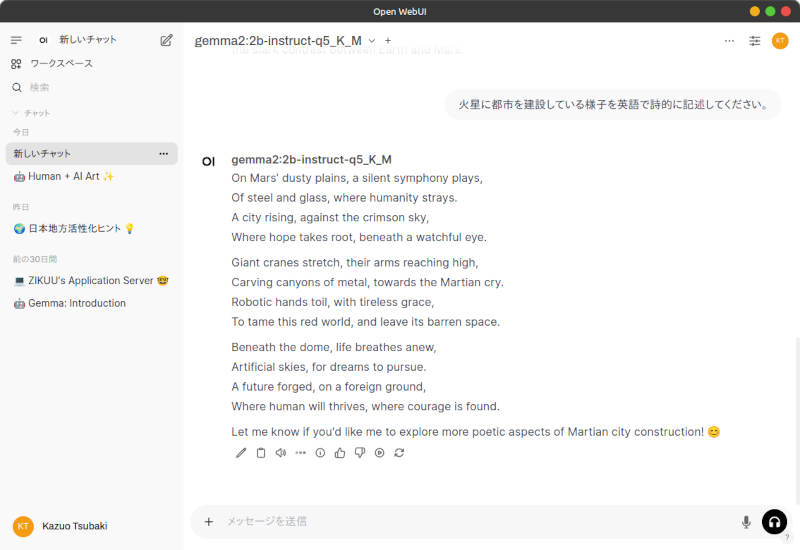
Open WebUIのチャット画面で、適当な言語モデルを選択して文章を生成します。
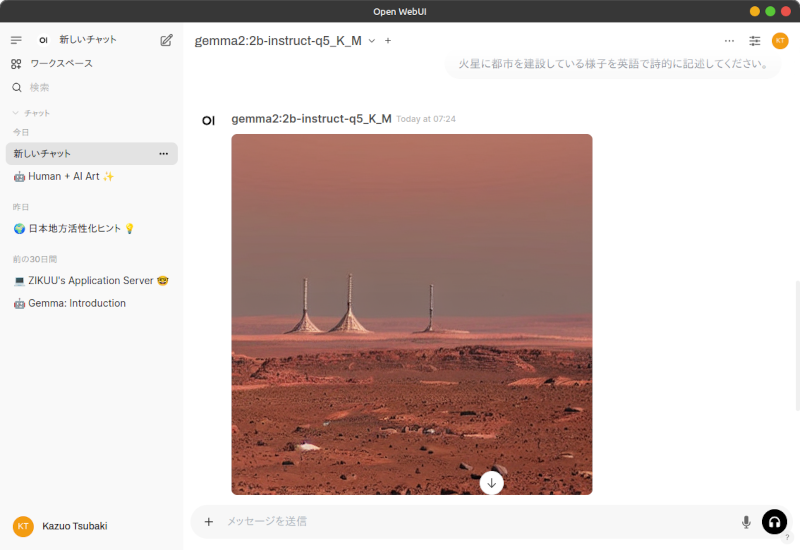
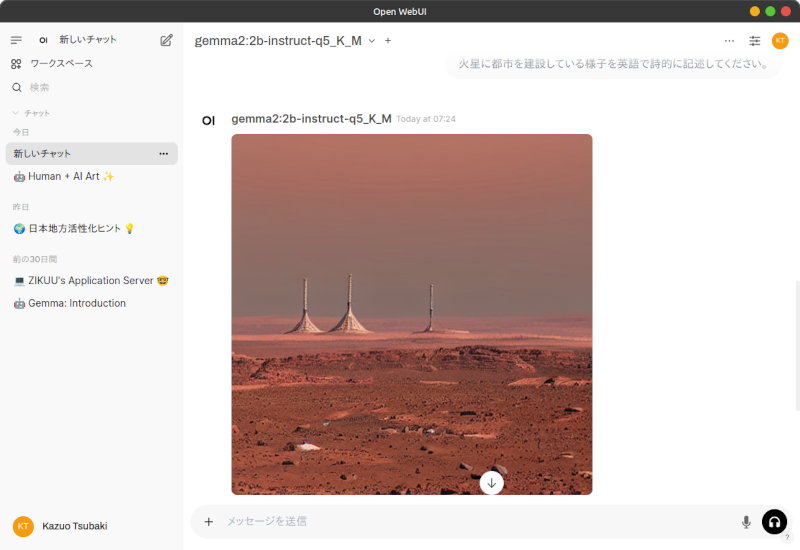
下の例では、「火星に都市を建設している様子を英語で詩的に記述してください。」というプロンプトで文書生成してみました。
文章生成処理が終わったら、生成された文書の下に並ぶアイコン群の中の「Image Generation」ボタンを押します。これでComfyUIに画像生成リクエストが送信され、生成された画像が下のスクリーンショットのように表示されます。
文章生成AIで「○○のStable Diffusion用プロンプトを作成してください」のようにしてプロンプを生成させて、それをComfyUIやStable Diffusion WebUIにコピペして画像生成しても良いのですが、今回の方法ならプロンプト作成から画像生成までをワンストップで行えて少し楽ができますし、実用性も少し高まるのではないかと思います。
