前回の続きです。
AI塾長やKAGURAの基盤になるソフトウェアスタックなので、これを何とか形にしないと先に進めません。
フルスタックのWebフレームワークにするのが目標ですが、データベース処理部分だけは先に仕上げてしまいます。
抽象クラスの設計と実装が連続するので、動くものが見られない時間が長いです。頭の中で動いている姿を想像しながらの作業です。
今日までの成果。
ZWAコアの実装が、ひとまず一周しました。
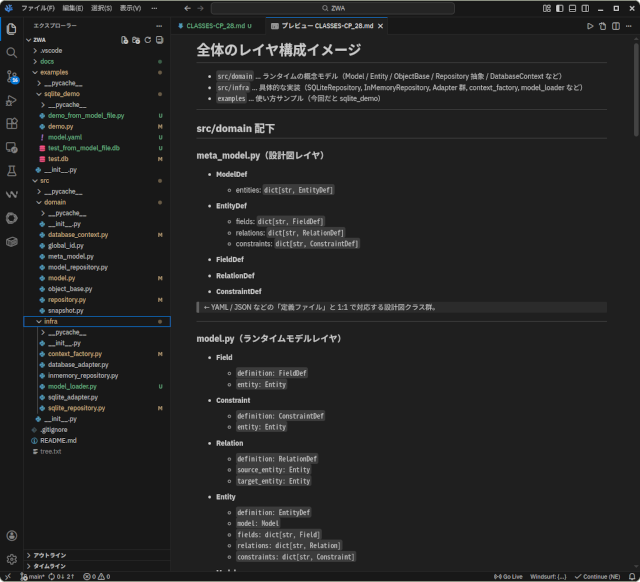
いまのZWAは「Entityスタック+Context+YAMLモデル」で、データアクセスの骨組みが動いています。
設計図のレイヤーには ModelDef / EntityDef / FieldDef がいて、ここが「どんなエンティティを扱うか」を決めます。実行時にはそれが Model / Entity / ObjectBase に展開され、行データはすべて ObjectBase という共通の入れ物で扱います。NeXTのEOFやAppleのCoreDataを知っている人なら、「あれか?!」となると思います。
データベース側は、Repository 抽象と SQLiteRepository に集約しました。プログラマーは基本的に Repository を直接触らず、DatabaseContext を通して add / list / delete / commit だけを呼べばよい構造になっています。
面白いのは、接続情報までをモデルファイルに追い出した点です。model.yaml に
- エンティティ定義
connection.engine(例: sqlite)connection.database(DBファイルのパスや接続情報)
を書いておくと、
load_model_from_yaml()で Model を読み込みopen_database_context(model)で接続先が自動で決まりctx.ensure_schema()でテーブルが用意されObjectBaseを使って CRUD が実行できる
という流れになります。
プログラマーが意識するクラスは「Model / Entity / ObjectBase / DatabaseContext」と、open_database_context() くらいまで。SQLiteかPostgresか、といった具体的な話は裏側に追いやられました。
まだ最小限の機能ですが、「定義ファイルからモデルを起こし、そのモデルに従ってデータベースとやり取りする」というZWAの中心部分は、すでに動き始めています。
次は、リレーションのLazyフェッチとか、複数種類のデータベースへの同時接続とか、トランザクション管理といった機能を入れていく段階です。
