モノづくり塾のGPU搭載PCで試しました。
PCのスペックはCPU Core i5 13500、RAM 64GB、GPU RTX A4000です。OSはUbuntu 22.04 LTS。
塾生がAIの勉強ができるようにと用意したPCですが、ファインチューニングやRAGなどを行ってもっと実証実験的なことをしてみたいと思っています。例えばKubernetesを使ってGPUクラスターを構築して塾内でLLMをホスティングし、特定分野に特化した尖ったLLMを開発運用するみたいな。
CPUが結構忙しいです。レスポンスも遅いでの70bを動かすならもっと高速なCPUを搭載にする必要があります。全コアの稼働率を平均すると30%前後ですから、マルチコア性能よりもシングルコア性能の高いCPUを選んだ方がいいのかな。RAMはあまり使っていないようです。
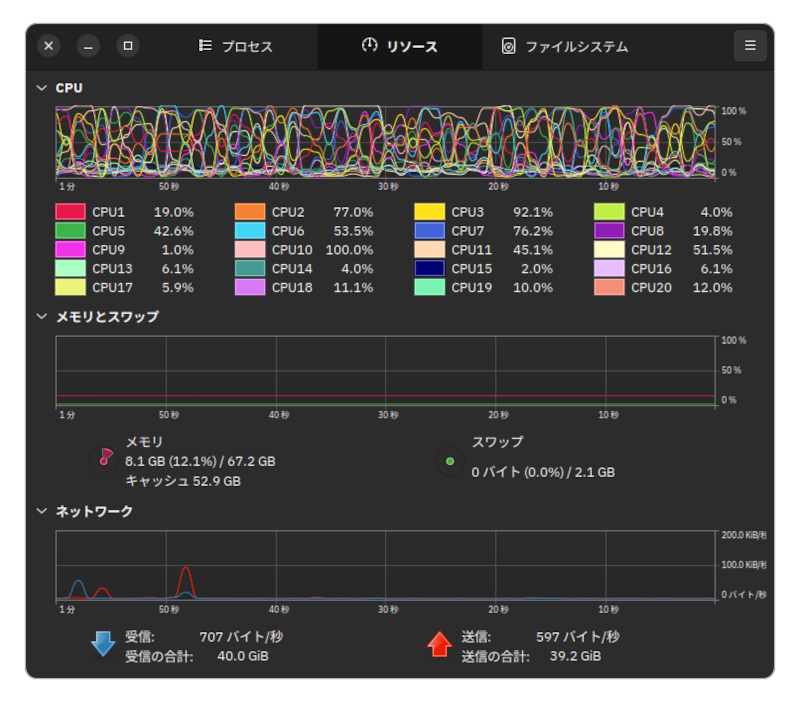
GPUは16GBのVRAMを使い切る感じです。消費電力が最大で50Wほどですのでフル回転というわけではありません。
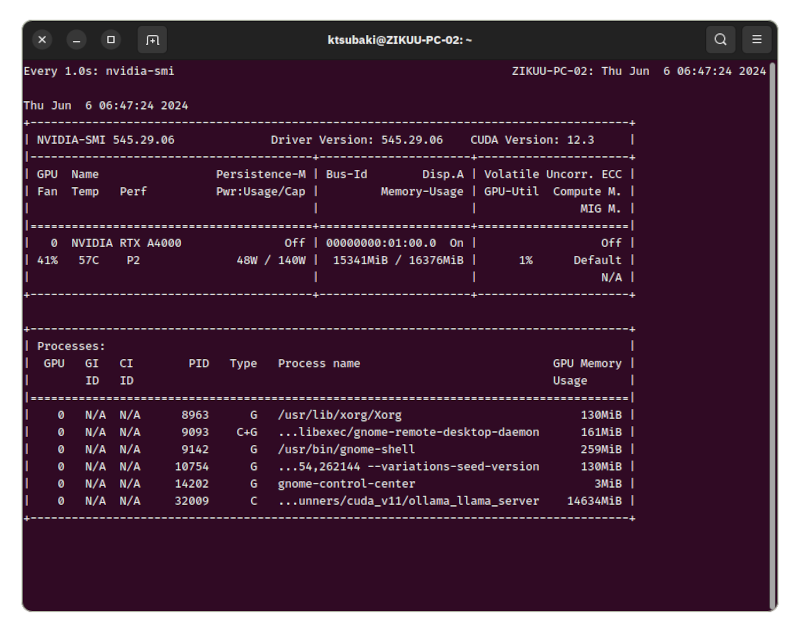
A4000は消費電力が控え目で耐久性がありそうなのが魅力ですが、それほど速いGPUではないので、もっと速いGPUと速いCPUの組み合わせならだいぶ使える感じになるのではないでしょうか。これが8bだとストレスがまったくない高速なレスポンスが得られて、このままでも使える感じです。
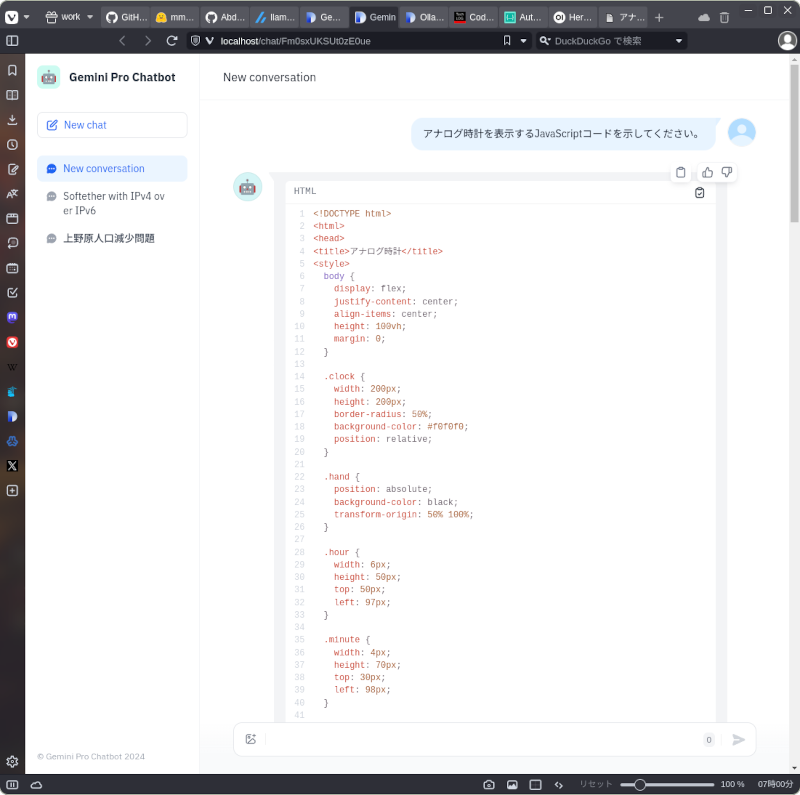
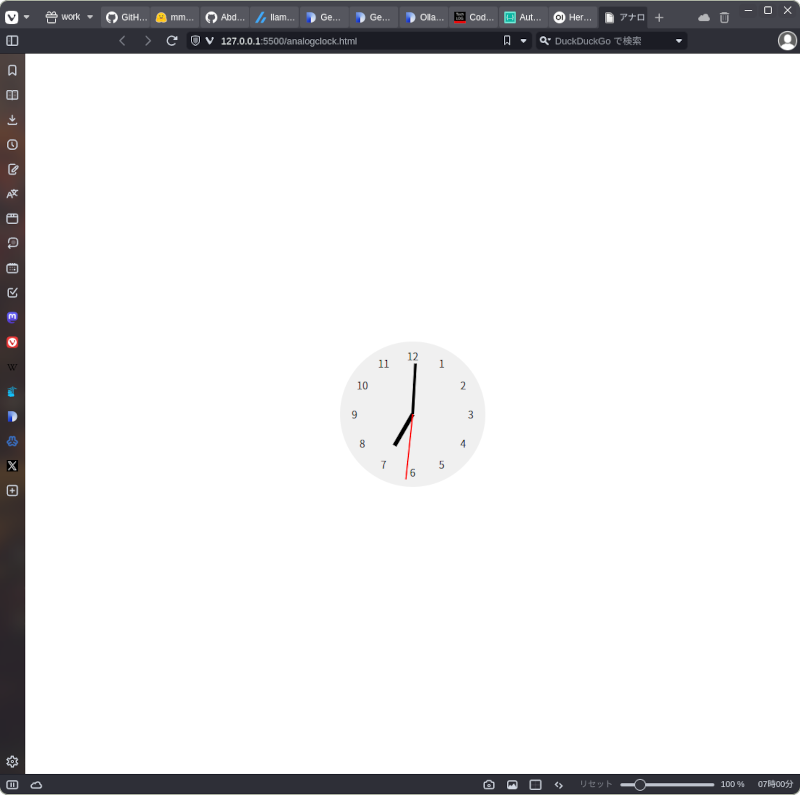
ちなみにこれは「アナログ時計を表示するJavaScriptコードを示してください。」という質問を投げたときのものです。
同じことを8bでも試しましたが同じデータを学習しているようで生成されたコードはまったく同じでした。
同じことをGemini 1.5 Proでも試しました。こちらはホスティングされているLLMをDifyから使用しています。
生成されたソースコードをVS Codiumにコピペして保存。ソースコードに手は入れていません。
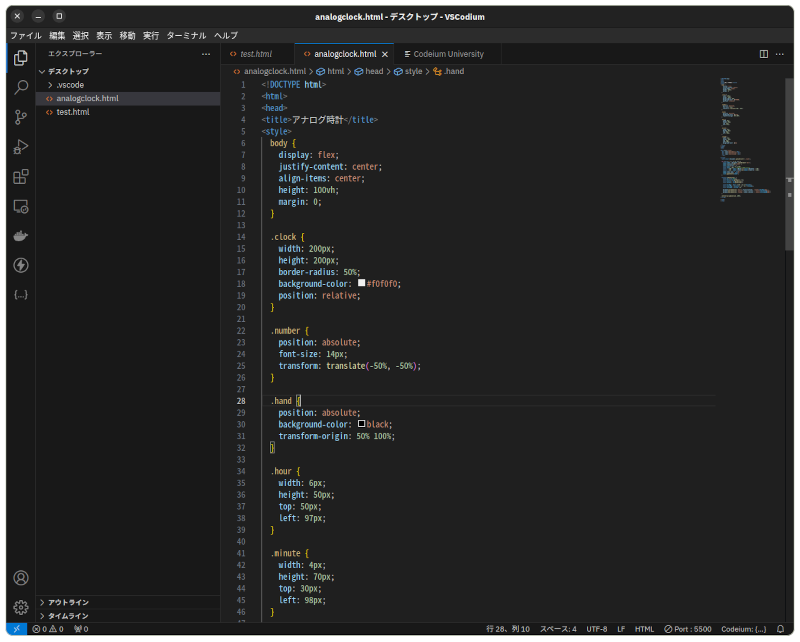
そして実行。正しくアナログ時計が表示されて動きます。
Gemini 1.5 Proの場合はHTML+CSS+JavaScriptが一体となったコードを生成してくれてLlama3が生成したものより親切でした。
Llama3が生成したコードにはCSSが含まれていませんでしたが、「CSSも含めてください」としたらCSSも出てきました。面白いことに最初にCSSを含めて欲しいとしたときはシレっとCSS無しのコードを出力したこと。「CSSが入ってないよ」としたらCSSを出力してきました。プログラムの正しさについてはGemini 1.5 Proと同等かなという感じでした。