もう一度アートについて
生成AIに校正してもらった過去の投稿を再掲載します。比較して読んでみると如何に私の文章が下手くそなのかがわかって恥ずかしいですが、主張したいことが抜けることもなく校正されるので、文章の下手な私が言うのも変ですが使えるなと … 続きを読む
生成AIに校正してもらった過去の投稿を再掲載します。比較して読んでみると如何に私の文章が下手くそなのかがわかって恥ずかしいですが、主張したいことが抜けることもなく校正されるので、文章の下手な私が言うのも変ですが使えるなと … 続きを読む

初めてやることなので何が正解なのかがよくわかっておらず、天体望遠鏡の光軸がなかなかピッタリと決まりません。 そこで使いにくかったコリメーションリングを作り直しました。 そしてコリメーション用のアイピースも作りました。 望 … 続きを読む

3Dプリンターの出力がぐちゃぐちゃでした。 原因は印刷物がベッドに定着せずに浮いてしまったこと。 対処方法は糊を塗るのが普通らしいですが、マスキングテープでも良いということでやってみました。 無事に印刷終了しましたが、不 … 続きを読む

自宅を21時半に出て塾に到着したのは23時半。道中、10頭ほどの鹿に遭遇しました。4頭は道志みちから藤野に抜ける篠原の峠で、6頭は塾のすぐ近くで。前回来たときはイノシシの親子に遭遇してビックリしましたが、今日はもっとビッ … 続きを読む
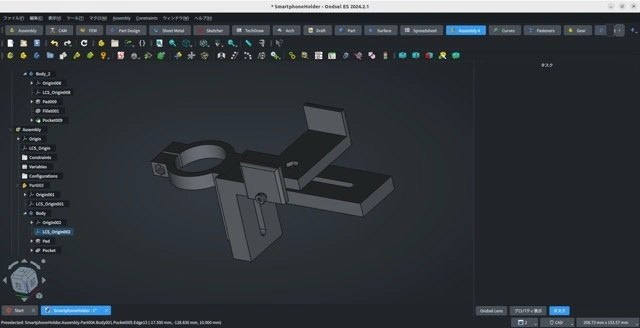
そろそろ望遠鏡が完成するので、次は天体写真を撮るための準備です。 接眼部に取り付けるスマートフォン用のホルダーを設計しています。 市販のものを買っても良いのですが、一旦は自作して使い勝手を評価します。使いにくかったり機能 … 続きを読む

注文していた部材(インサートナット)が届いたので最終組み立てに入りました。 一旦全バラ。 ハンダゴテで熱しながらインサートナットを埋め込みます。プラスチック素材ならではの方法ですね。 15分もあれば終わると思っていました … 続きを読む

昨夜は21:00に大船の自宅を出て22:30に上野原のモノづくり塾に到着。信号の繋がりが良くていつもより速く着きました。 ここ数日は猛暑日が続いています。塾の建屋内はかなり暑いです。これを書いている今はスポットクーラーの … 続きを読む