先日、Ollamaを動かした話を投稿しましたが、その続きとしてローカルで動いているOllamaをDifyから使ってみました。
DifyとOllamaはともにDockerで動かしています。
今回はGPU非搭載のノートPCでの試行だったので、使用するモデルはLlama3の4ビット量子化したものです。
Ollamaがローカルで稼働している状態でDifyからモデルプロバイダーとしてローカルのOllamaを指定してモデルを追加します。モデル名はOllamaで追加したモデル名と同じです。
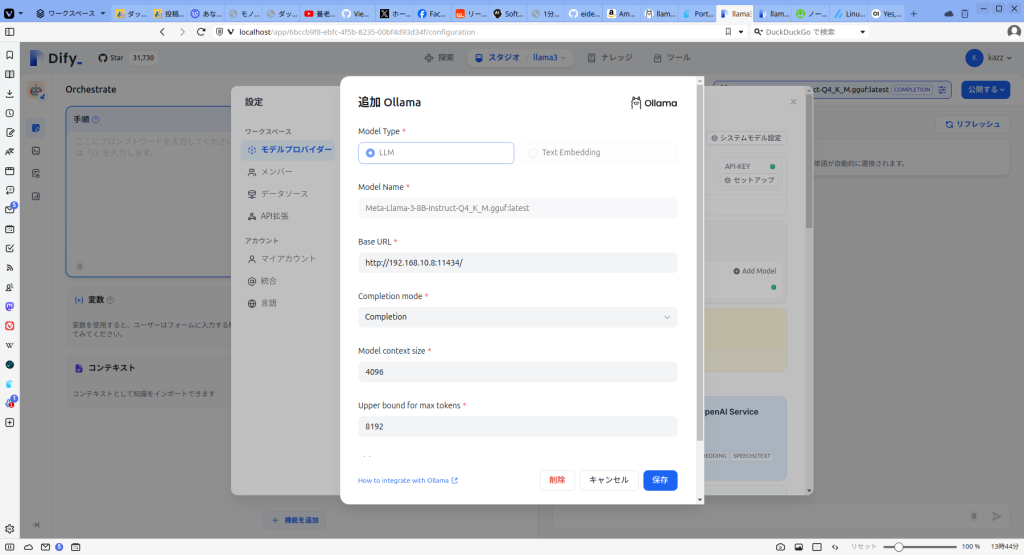
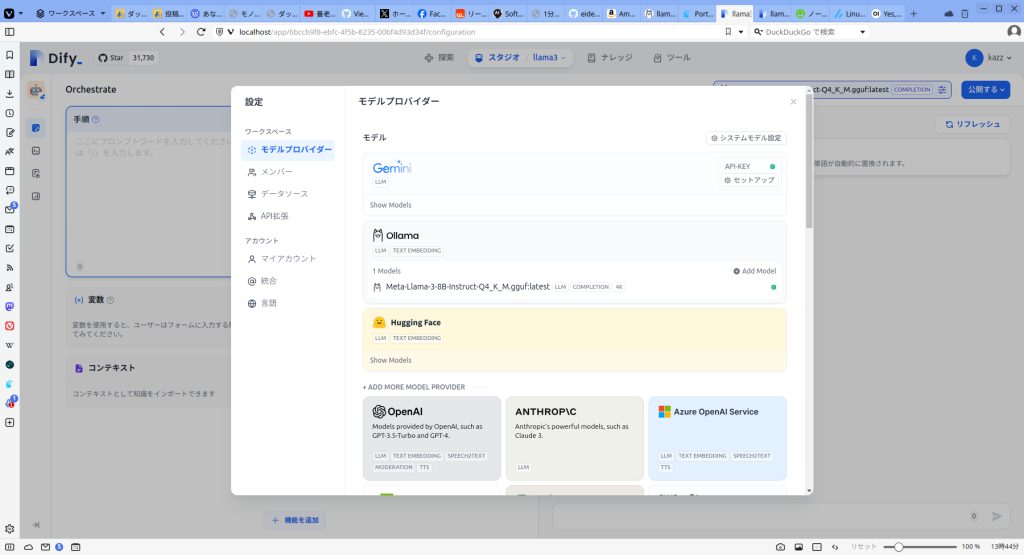
モデルが追加された様子。
チャットボットを作って動かした様子。
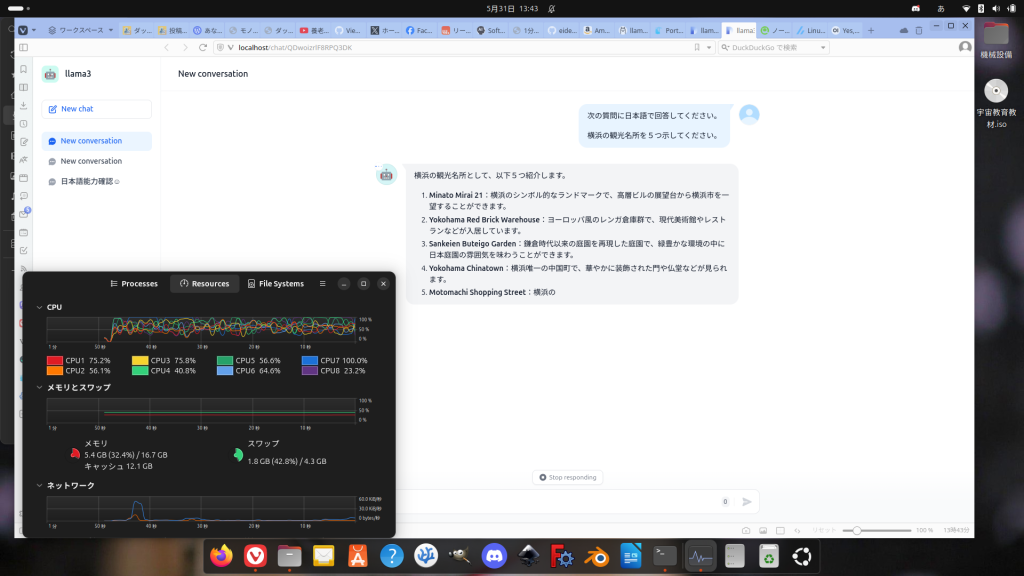
この方法だとOllamaで使えるモデルならばローカル環境でDifyを使ったAIアプリケーションから利用できて実験や娯楽の幅が広がります。
動かしたPCは第8世代Core i7搭載のノートPCでした。さすがに処理速度は実用に耐えられないくらい遅いです。そこそこのGPUを載せたPCサーバーを一台用意して、組織内でLLMをホスティングして使えばいろいろと試せそうです。モノづくり塾のアプリケーションサーバーにもNVIDIAのGPUを載せたくなりました。
