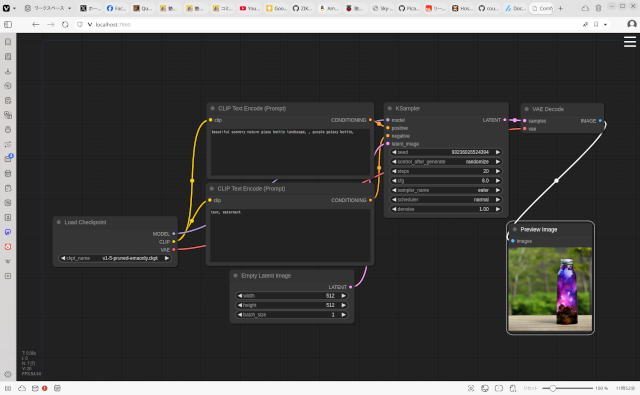
Open WebUIには画像生成AIを呼び出して画像を生成する機能があって、Stable DiffusionやComfyUIと連携できます。
上のスクリーンショットはComfyUIの画面です。これは画像生成のワークフローを設計するソフトウェアで、設計したワークフローをファイルに書き出し、その内容に合わせてOpen WebUIを設定します。
そうすると、Ollamaを使って画像生成用のプロンプトを生成し、そのプロンプトをComfyUIに渡して画像生成させるという合わせ技ができます。
これの利点として、
- 画像生成プロンプトを考える時間を短縮できる
- ネガティブプロンプトをComfyUI側のワークフローの中で変更することでプロンプトチューニングができる
などが考えられます。
スケーリングやチューニングもやり易くなるでしょう。
私の場合は、Ollama、Open WebUI、ComfyUIをDockerで運用しています。現状では公式のインストール方法にならって、この3つのソフトウェアをDockerで個別に起動していますが、今回紹介した用途に合わせて一つのDocker Composeファイルにまとめることも可能でしょう。
モノづくり塾のアプリケーションサーバーには外部GPUが取り付けられていないので、GPU搭載機で個別に動かして試しているという現状ですが、AI関連の学習(には運用をするところまでの知識習得が含まれる)をちゃんとやろうと思うと、何らかの運用機材が必要です。やらなければならないことが増えるばかりです。
現時点では、AIにおまかせで何でもできるという状況ではありませんが、多少の問題や能力不足があっても、そろそろ学校教育の場でもAIを使う・作る方法を教え、行政や企業もAIを理解して活用した方が良いですし、AIで出来ることはAIに移行して働き方を変えていく必要があると考えます。
