上の画像はOllamaとOpen WebUIを使ってRAGシステムを実現した様子です。
ベクターデータベース(ナレッジ)にはこのブログのすべての記事からテキストを抽出したデータとモノづくり塾の所在地や私のプロフィールなどを登録してあります。
このナレッジと既存の言語モデル(この場合はGoogleのGemma3 4b)を結びつけて新たなモデルを定義します。
チャットの際に、このモデルを選んで通常通りテキストプロンプトを入力して言語モデルとやり取りします。
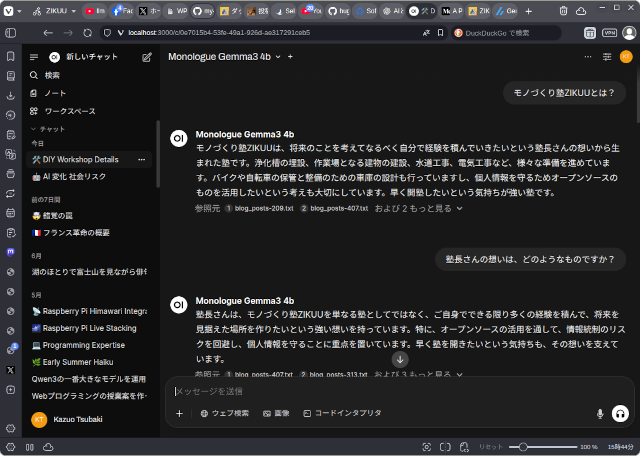
ナレッジを参照して文章を生成しているのがわかります。
ですが、ナレッジの順位付け(Reranking)ができていないので、本当に欲しい情報を得るのは少し難しいように思います。
だいぶ高性能になってきたというものの、ローカルLLMは、こういう「出来るけど今一つ」「とりあえず動いている」というものが多いんですよね。ChatGPTなどの商用サービスのような性能を期待することはできません。
今、LLMのファインチューニングについて試行していますが、結局のところ、学習用のデータセットを如何に高品質に大量に用意するかというところに行き着きそうです。ChatGPTに文章からデータセットを作る支持をするとなかなか良いと思えるデータセットを作ってくれますが、ローカルLLMでは今のところ同等の結果は得られていません。
思い描いているのは、
- 定期的に塾のブログや資料を集め
- ベクターデータベースに登録するデータを生成し
- ファインチューニング用のデータセットを生成し
- 夜中にベクターデータベースへの登録とファインチューニングを終わらせる
というワークフローを自動化すること。先日紹介したn8nを使えばやれそうですから、個々の機能を実験して良さそうな手法を見つけて組み上げていくことになるでしょう。

「OllamaとOpen WebUIを使ったRAGシステム」への1件のフィードバック