
昼間は暑くて何もする気になりません。最近は、完全に昼夜逆転した日々を送っています。昨夜から今朝にかけてコンピューターの前に座ってLLMのチューニングを試みていました。朝日が眩しいです。
今回のテーマは「Mistral 7BをUnslothを使ってQLoRAチューニングを行う」です。
UnslothはVRAMの使用量を節約してLLMをチューニングできるライブラリーです。
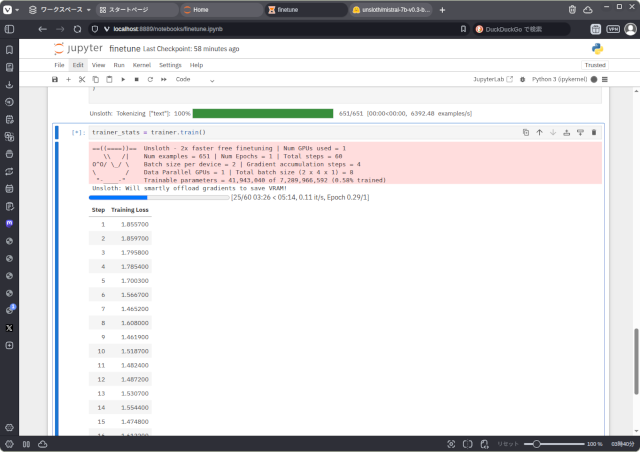
今回はVRAMの使用量に着目して作業しました。使用したデータセットはこのブログから抽出したテキストに少しデータを追加した690件ほどのもので、Alpaca形式です。
これはMistral 7Bの4ビット量子化モデルをチューニングしたときのVRAM使用量です。VRAM使用量は8GB以内に収まっています。これなら、多少速度が遅いのを我慢すれば、Core i5/Ryzen 5 と GeForce RTX 3060 12GBを組み合わせて比較的安価に組んだPCでやれます。
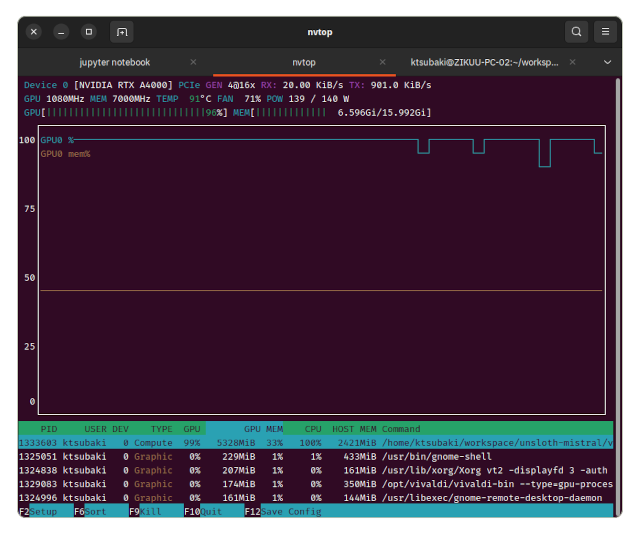
ちなみに、Gemma 3 12Bの4ビット量子化モデルでトレーニングしたときのVRAM使用量を確認したのが下のスクリーンショットです。
塾のPCはCore i5 13500 + RTX A4000の組み合わせです。16GBのVRAMでギリギリやれる感じです。A4000は最新のゲーム用GPUに比べると処理速度で劣ります。ターンアラウンドを速くするには同価格帯のゲーム用GPUを使った方が良いと思います。いずれ、もっと高速なGPUを手に入れて、A4000はサーバーに移設して推論専用にしたいです。
結果は期待していたものには程遠いものになりました。今後も試行錯誤を続けていきます。次のテーマはデータセットを綺麗にすることと、チューニングパラメーターの調整です。「これはこういう仕組みになっている」「ここを変えるとこうなる」といったことが理解できるまでは、時間がかかっても良いのでしぶとく取り組みます。
参考までに、今回実行したコードです。おかしなところがあったらご指摘ください。
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer
from transformers import TrainingArguments, TextStreamer
max_seq_length = 2048
dtype = None
load_in_4bit = True
fourbit_models = [
"unsloth/mistral-7b-v0.3-bnb-4bit",
]
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/mistral-7b-v0.3-bnb-4bit",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = True,
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text": texts, }
pass
from datasets import load_dataset
dataset = load_dataset("json", data_files="datasets/qlora_dataset.json", split="train")
dataset = dataset.map(formatting_prompts_func, batched = True)
training_args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 60,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
lr_scheduler_type = "linear",
seed = 3407,
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
output_dir = "outputs"
)
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = training_args
)
trainer_stats = trainer.train()
print(trainer_stats)
trainer.save_model("./trained")
tokenizer.save_pretrained("./trained")
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
alpaca_prompt.format(
"質問に対して詳細かつ丁寧に回答してください。",
"モノづくり塾ZIKUUの塾長のプロフィール",
"",
)
], return_tensors = "pt").to("cuda")
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)

「知識蓄積・共有の研究〜その2 Unslothを使ったファインチューニングの試み」への1件のフィードバック