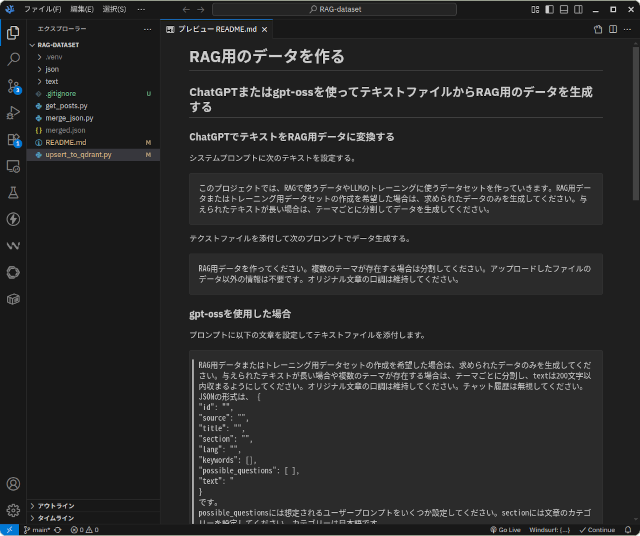
今日はこのブログの記事をダウンロードして、GPT5やgpt-ossで作成したRAG用をQdrant ベクターデータベースに登録するプログラムを書きました。プログラムはすべてPythonで記述。ネットを探せばサンプルコードがたくさん見つかるので、難しいプログラムはないと思います。
ブログから記事の本文をダウンロードするプログラムは簡単なものです。
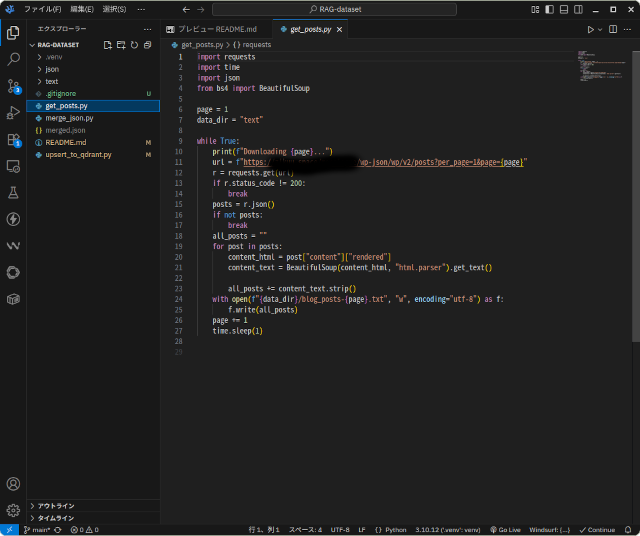
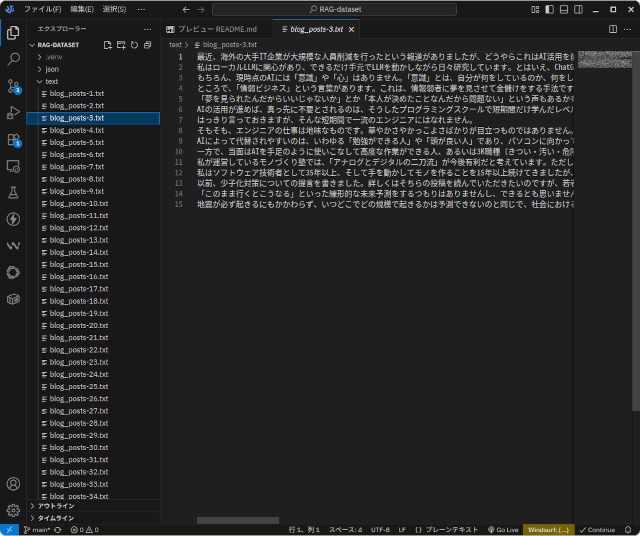
このプログラムを使ってブログからダウンロード記事の本文はこのような形です。
それをGPT5やgpt-ossの力を借りてJSON形式に変換したのがこちら。以前の投稿でも触れましたが、gpt-ossがとても優秀で、少しの工夫でGPT5に劣らない結果を得られますし、ローカルで動くgpt-ossの方がレスポンスが速くて使い心地が良いです。
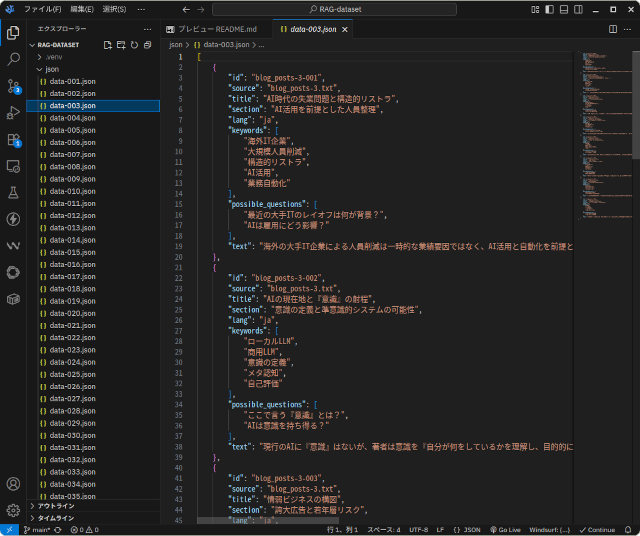
こういう形に構造化されていると、後々、色々と変換作業が楽になります。
ここまでの作業は本来ならば自動化したいと思っていますが、現時点では変換されたデータを個々に確認するために個別にプログラムで処理しています。これが結構大変ですが、もし生成AIの力を借りなかったら、この変換作業に10倍くらいの時間がかかるはずです。これでも相当の省力化が達成されています。
この投稿を書いている時点で、ブログ記事は650本ほどあります。ダウンロードした本文のテキストファイルが650あって、それをJSON形式に変換する際に本文内に含まれるテーマ毎にデータを分割するので、最終的には3倍の2000個ほどのJSONデータができることになりますが、今日の時点では350個ほど変換したところで作業を中断しています。
変換したファイルは次のプログラムで1本にまとめます。
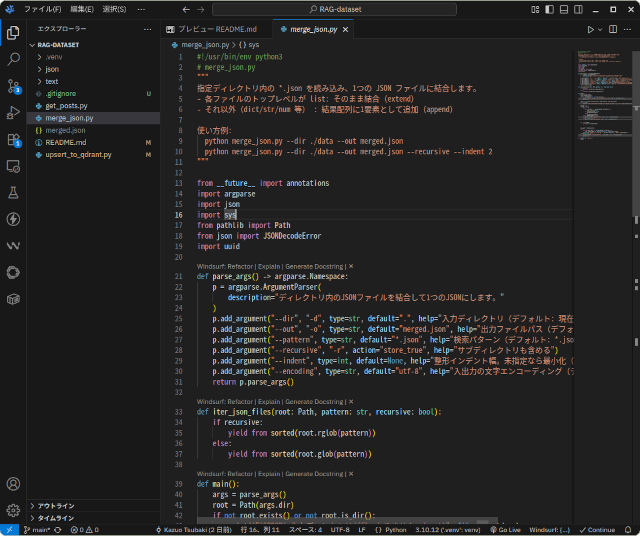
1本化したファイルは、このプログラムでQdrantに保存します。このプログラムを書くのに2時間ほどかかりました。
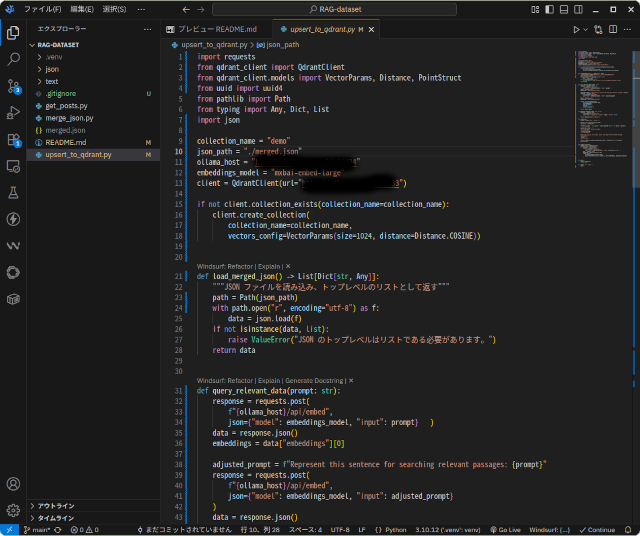
今回は埋め込みモデルにOllamaのmxbai-embed-largeを使いました。GPU非搭載の遅いサーバーで動いているOllamaを利用したので、350件のデータをQdrantに登録するのに5分ほどかかりました。GPU搭載機なら2000件でも1分程度で終わる処理だと思われます。
こちらがQdrantに登録されたデータです。
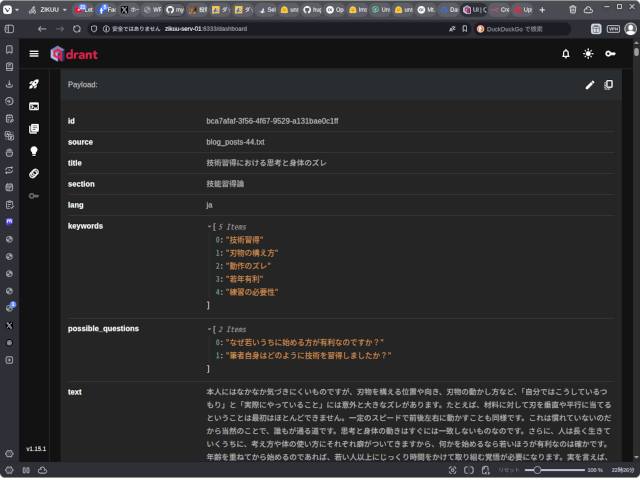
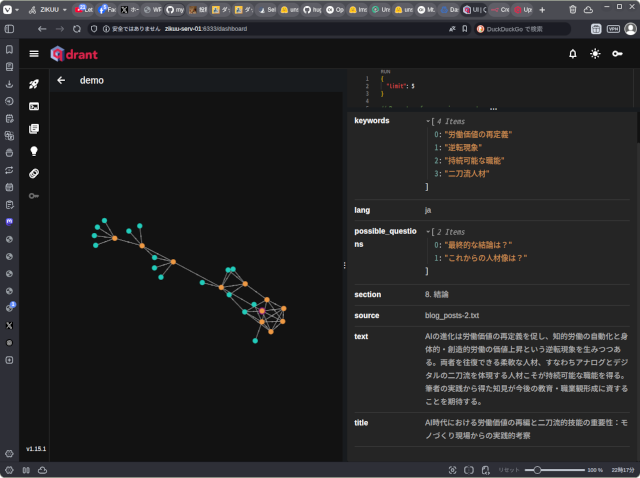
ベクターデータベースはデータの意味をベクトル値として保存したデータベースで、データとデータの近さを検索できるようになっています。Qdrantにはデータの位置関係をグラフ表示する機能があります。
今後の作業としては、
- JSONに未変換の残りのデータの変換を行う
- 再度、全データをQdrantに登録す
- RAGを試すプログラムを書いて効果を確認する
- 問題があればデータを見直して、2、3を繰り返す
という感じです。
余裕があれば、これらの一連のワークフローを自動化する方法を考えて実装したいところです。
プログラムとデータは塾生やスタッフがアクセスできるGitHubリポジトリに置いて共有して塾の教材にしています。

「RAG用データを作成してQdrantに登録する」への1件のフィードバック