LLM(生成AIの大規模言語モデル)とRAG(Retrieval Augmented Generation)のStreamlit(Python用のWebアプリケーション開発フレームワーク)を使ったサンプルプログラムを見つけたので、それを小改造して動かしてみました。
PDFを読み込んで、その内容について質問をするとLLMが要約して回答してくれるものです。理屈がわかれば比較的簡単に実装できそうなプログラムです。
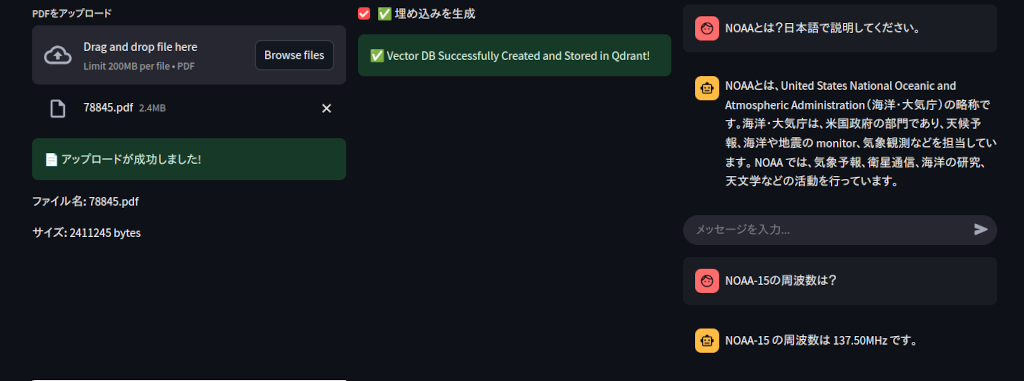
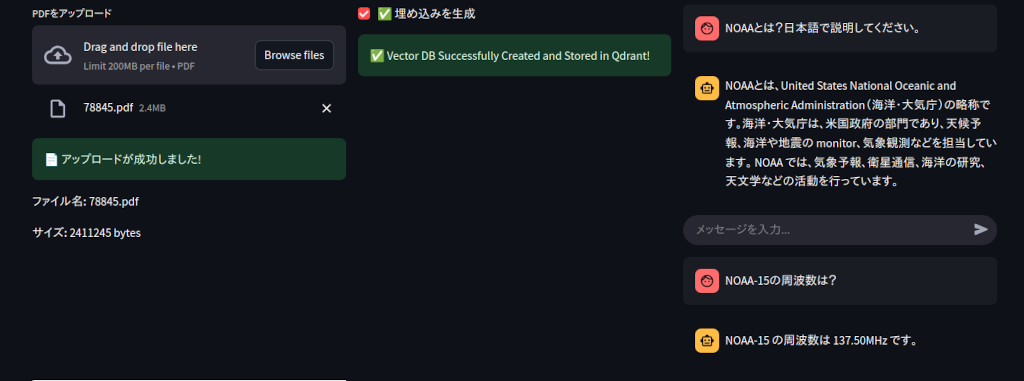
例えば、こんな気象衛星の解説文のPDFを読み込んで・・・

「NOAAとは?」「NOAA-15の周波数は?」みたいに質問すると、PDFの内容を加味して文章生成します。(ちなみにNOAAは一般的によく知られている気象衛星なのでRAGを使わなくても説明が得られます)
LLMが学習していない事を生成させたり生成文書の精度を高めたい場合は、
- ファインチューニングする
- フルチューニングする
- RAGを使る
などの選択肢があります。
1はパラメーターを部分的にチューニングする。これは計算量が少ないので小さなVRAMでもチューニングができる。
2は大きなVRAMが必要。大きな計算資源を使える場合にはこれ。
3は外部データベース(ベクターデータベース)から関連するデータを検索してLLMに投入するため、チューニングをする必要がない。
1と3、2と3を組み合わせると更に生成文書の精度を高められる。
社内のデータをLLMで扱う場合、ChatGPTやGeminiなどのクラウドサービスは社外に会社のデータを送信する必要があるのでセキュリティー上の問題がありますから、ローカル環境で稼働させたくなります。大きな計算資源を持たない企業には、フルチューニングという選択はないので、RAGを使うことになる場合が多いです。
汎用的なアプリケーションなら、ネット検索->ベクターデータベース化->LLMで文書生成という形式が良いし、企業内の資料を使って文書生成するなら、社内文書->ベクターデータベース化->LLMで文書生成という形です。これらを組み合わせるのも良いですね。
社内文書の部分は、裁判の判例だったり、特許情報だったり、企業の知財だったりします。
会社や役所の中に、こういうプログラムをパッと作って、業務に合わせた生成AIアプリケーションを作れる人がいると便利ですよね。
十分に暇があったら、もっと高機能なものを作ってみようと思います。
