先日、このブログをクローリングして投稿を機械学習用のデータセットに変換するプログラムを書きました。今回はその続きで、そのデータセットを使った既存の学習済言語モデル(Pretreined Language Model)をLoraチューニングするプログラムを書いてみました。(上のスクリーンショット)
使用したコンピューターはCore i5 13500 CPUとNVIDIA RTX A4000 (16GB VRAN)を搭載したもの。対象とした言語モデルはGoogleのGemma 3 1Bのインストラクションチューニング済のものです。
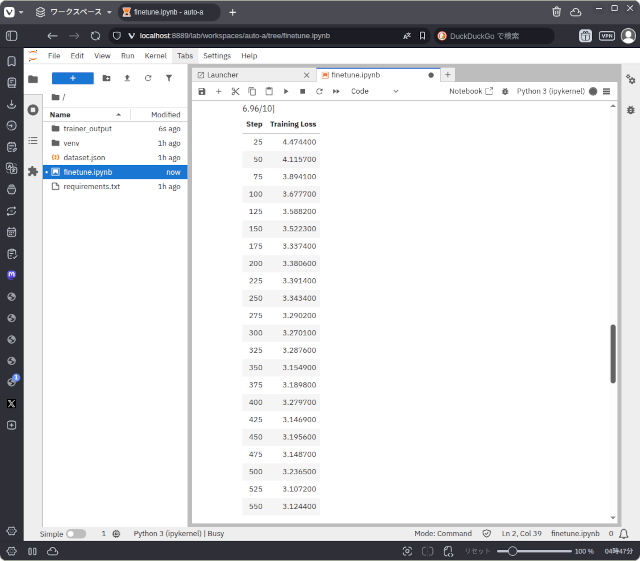
結果は失敗。学習ロスが減らず実用的なものにはなりませんでした。
この程度の処理ですと、コンピューターの処理速度に大きな不満はないものの、VRAMはもっと欲しいです。このコンピューターの構成では1Bのモデル、トークン長128くらいが限界で、14GBほどのVRAMを使っていました。
ハイパーパラメーターは何度も変更して試しましたが、良い結果は得られませんでした。
データセットの質が悪い(ブログ投稿そのままは望ましくない)ということかもしれません。
参考までに、トレーニングコードは次のようなものです。
/* データセットを読み込む */
from datasets import load_dataset
raw_data = load_dataset("json", data_files="dataset.json")
/* トークナイザーの準備 */
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-3-1b-it"
)
/* データセットの前処理 */
def preprocess(sample):
sample = sample["prompt"]+ "\n" + sample["completion"]
tokenized = tokenizer(
sample,
max_length=128,
truncation=True,
padding="max_length"
)
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
data = raw_data.map(preprocess)
/* チューニング対象のモデルの準備 */
from peft import LoraConfig, get_peft_model, TaskType
from transformers import AutoModelForCausalLM
import torch
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-3-1b-it",
device_map="cuda",
torch_dtype=torch.float16,
attn_implementation='eager'
)
/* LORAの設定 */
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
target_modules=["q_proj", "k_proj", "v_proj"]
)
model = get_peft_model(model, lora_config)
/* トレーナーの準備 */
from transformers import TrainingArguments, Trainer
train_args = TrainingArguments(
num_train_epochs=10,
learning_rate=3e-4,
logging_steps=25,
fp16=True
)
trainer = Trainer(
args=train_args,
model=model,
train_dataset=data["train"]
)
/* トレーニング実行 */
trainer.train()
/* トレーニング済のモデルとトークナイザーの保存 */
trainer.save_model("./trained")
tokenizer.save_pretrained("./trained")学習ロスは1.0以下が目標ですが、3.0までしか減りませんでした。
以下のコードがファインチューニング後のモデルを使った推論を行うものです。
from transformers import pipeline
ask_llm = pipeline(
model="./trained",
tokenizer="./trained",
device="cuda"
)
print(ask_llm("プロンプト")[0]["generated_text"])今回のところは、手法が理解できたということが収穫ということにして、課題を整理してから再挑戦します。

「知識蓄積・共有の研究〜その1 LLMファインチューニングの試み」への1件のフィードバック