数日前の「GPT5とgpt-ossで同じ処理をしてみる」という投稿で、このブログの投稿から本文のテキストを抜き出し、後々、加工がしやすいようにJSON形式に変換する処理をしたことを書きました。
LM Studioでgpt-ossを使ってデータを変換している様子を動画にしました。アップロードしたファイルはプレーンなテキストファイルです。
ChatGPT 5とgpt-oss 20bでほぼ同程度のデータ生成が行えています。どちらも???という文書を生成することがありますが、手直しが必要になるのは少しだけです。
こういう変換処理を人手でやるのって大変ですよね。
以下がプロンプト設定です。
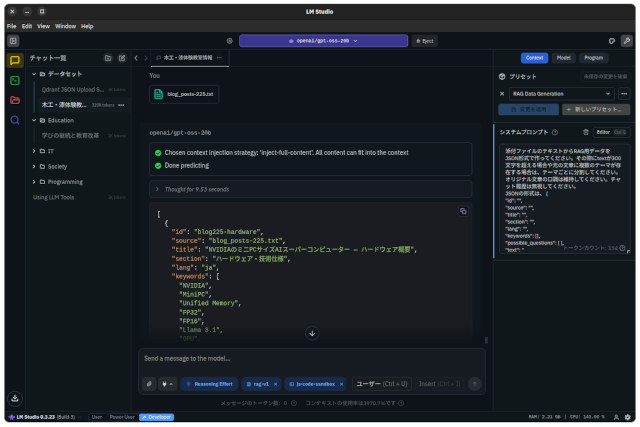
gpt-ossでのプロンプト設定
システムプロンプを次のように設定し、テクストファイルをアップロードするだけの簡単な操作で変換が行われます。
添付ファイルのテキストからRAG用データをJSON形式で作ってください。その際にtextが300文字を超える場合や元の文章に複数のテーマが存在する場合は、テーマごとに分割してください。オリジナル文章の口調は維持してください。チャット履歴は無視してください。
JSONの形式は、 {
"id": "",
"source": "",
"title": "",
"section": "",
"lang": "",
"keywords": [],
"possible_questions": [ ],
"text": "
}
です。
possible_questionsには想定されるユーザープロンプトをいくつか設定してください。sectionには文章のカテゴリーを設定してください。カテゴリーは日本語です。
本文が長い場合や複数のテーマがある場合は本文を分割する、本文テキストを期待する想定されるプロンプト、キーワード抽出、タイトル作成などをLLMが行います。
ChatGPT 5でのプロンプト設定
同じ処理を行うために、ChatGPTでは、システムプロンプトを次のようにした上で・・・
このプロジェクトでは、RAGで使うデータやLLMのトレーニングに使うデータセットを作っていきます。RAG用データまたはトレーニング用データセットの作成を希望した場合は、求められたデータのみを生成してください。与えられたテキストが長い場合は、テーマごとに分割してデータを生成してください。ユーザープロンプトを次のようにしました。
RAG用データを作ってください。複数のテーマが存在する場合は分割してください。アップロードしたファイルのデータ以外の情報は不要です。オリジナル文章の口調は維持してください。
「GPT-OSSでテキストをJSONファイルに変換する様子」への1件のフィードバック