AIコーチがほぼ完成

コミュニティDX基本セット(案)に含める予定のAIコーチ for Discordのフル機能を実装してZIKUUでのテスト運用を開始しました。 うるさくないアドバイスになるように作りました。派手ではないものの、さりげなくみ … 続きを読む
コミュニティDX基本セット(案)に含める予定のAIコーチ for Discordのフル機能を実装してZIKUUでのテスト運用を開始しました。 うるさくないアドバイスになるように作りました。派手ではないものの、さりげなくみ … 続きを読む
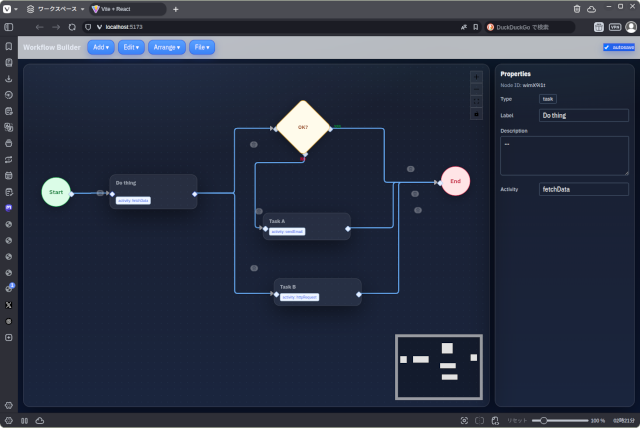
前回に引き続きAIに補助してもらってアプリケーションを作ってみました。今回はワークフローチャートを描画するWebアプリです。 WebフレームワークはReact+Viteを使用しました。ノード間の連結をマウスクリック&ドラ … 続きを読む
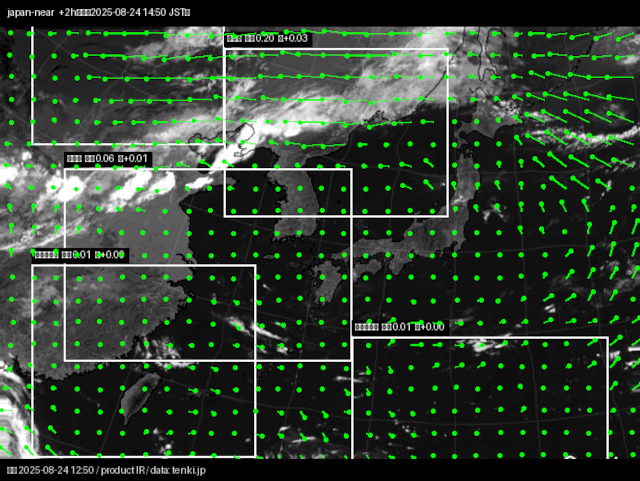
AIアシスタントとともにプログラミングを行うバイブコーディングと呼ばれているものをやってみました。 テーマは「tenki.jpから現時点、2時間前、4時間前、6時間前の気象画像をダウンロードし、2時間後の気象画像を予測生 … 続きを読む
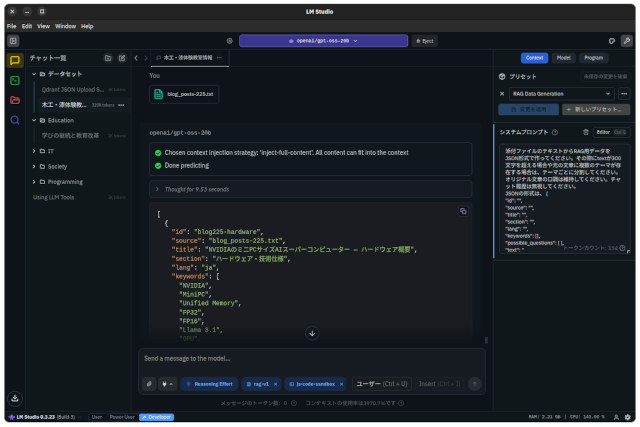
数日前の「GPT5とgpt-ossで同じ処理をしてみる」という投稿で、このブログの投稿から本文のテキストを抜き出し、後々、加工がしやすいようにJSON形式に変換する処理をしたことを書きました。 LM Studioでgpt … 続きを読む
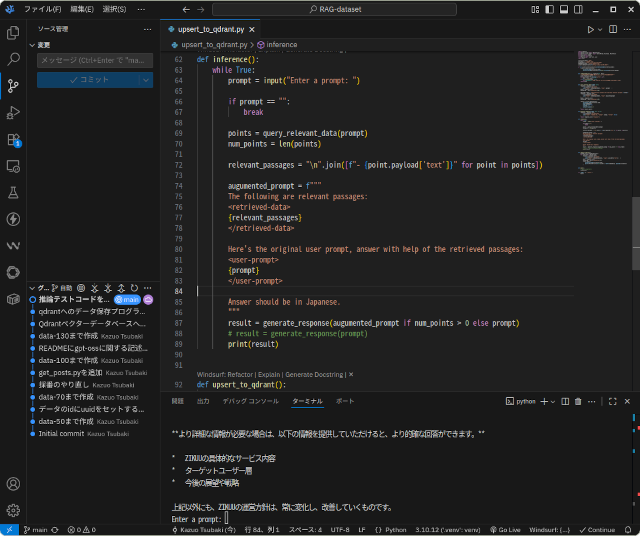
昨日行ったQdrantに登録したデータの効果を見るべく、簡単な推論コードを書いて試験しました。 「ZIKUUとは?」と「ZIKUUの運営方針を教えてください」という2つの質問に対してどう答えるかを試した様子です。 言語モ … 続きを読む
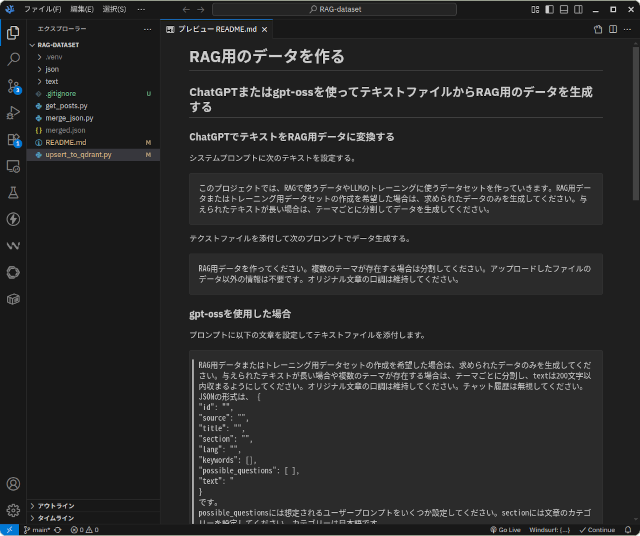
今日はこのブログの記事をダウンロードして、GPT5やgpt-ossで作成したRAG用をQdrant ベクターデータベースに登録するプログラムを書きました。プログラムはすべてPythonで記述。ネットを探せばサンプルコード … 続きを読む

以前にも触れましたが、モノづくり塾での活動で得た知識や技術をAIの文章生成に活かしたいと思っています。そのためにこのブログの文章のクローリングして本文を取り出すプログラムを書き、そのデータを使ってLoraやQLoraの手 … 続きを読む
先日公開されたOpenAIのgpt-ossですが、大きい方(120b – 1200億パラメーター)は80GBのVRAMを持つGPUがないと動かせませんが、小さい方(20b – 200億パラメーター … 続きを読む
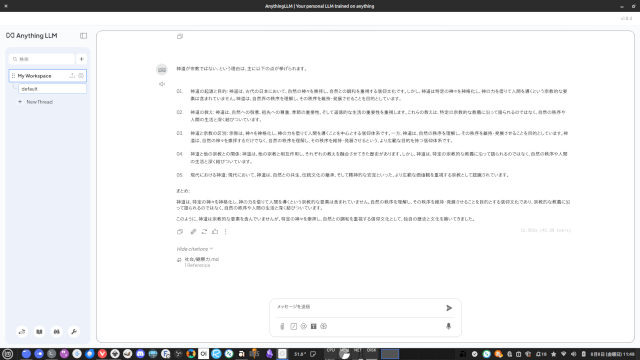
LLMを簡単に使うツールのAnythingLLM Desktopを使ってみました。AnythingLLMにはRAG機能や簡単なエージェント機能、ワークフロー機能が備わっていて、Open WebUIやLM Studioなど … 続きを読む
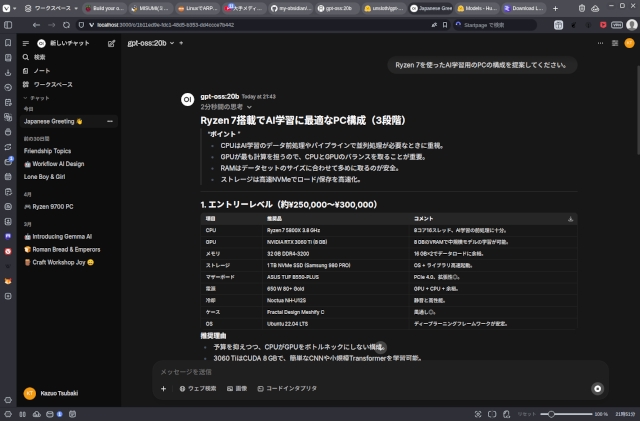
OpenAIのChatGPTのオープンソース版が公開されました。 生成AIの言語モデルに関して、オープンソースの定義があったような記憶があるのですが、そこでは確か、「学習コード、ウェイト、データセットがオープンであること … 続きを読む