知識蓄積・共有の研究〜その2 Unslothを使ったファインチューニングの試み

昼間は暑くて何もする気になりません。最近は、完全に昼夜逆転した日々を送っています。昨夜から今朝にかけてコンピューターの前に座ってLLMのチューニングを試みていました。朝日が眩しいです。 今回のテーマは「Mistral 7 … 続きを読む
昼間は暑くて何もする気になりません。最近は、完全に昼夜逆転した日々を送っています。昨夜から今朝にかけてコンピューターの前に座ってLLMのチューニングを試みていました。朝日が眩しいです。 今回のテーマは「Mistral 7 … 続きを読む
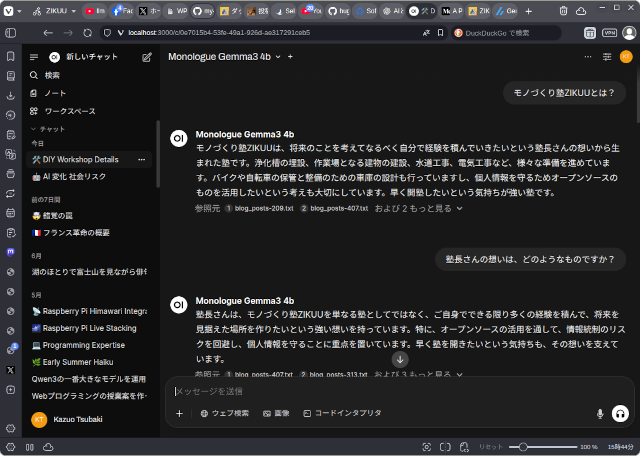
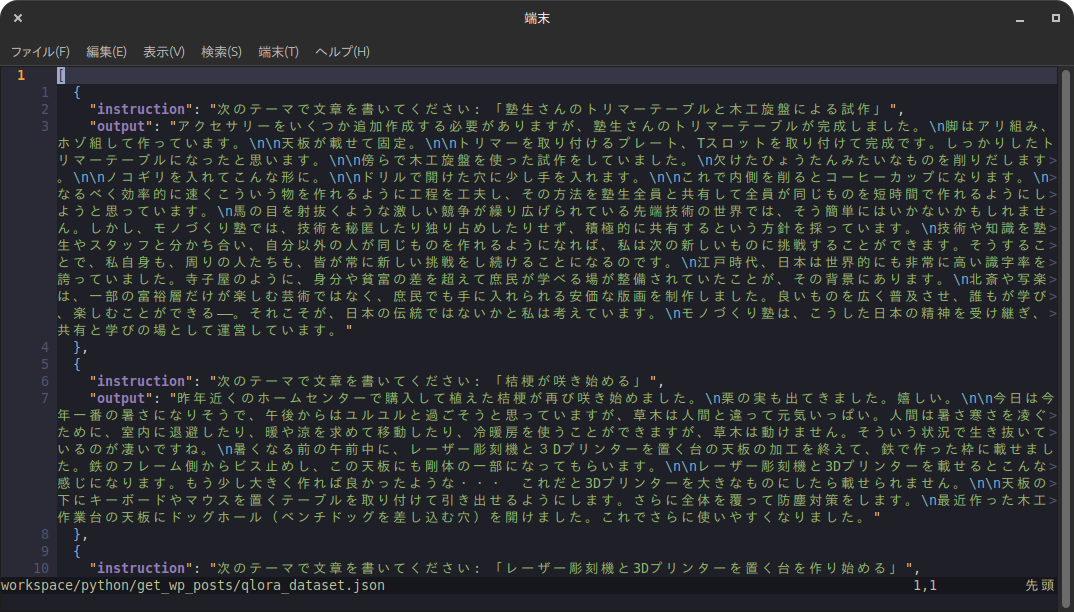
上の画像はOllamaとOpen WebUIを使ってRAGシステムを実現した様子です。 ベクターデータベース(ナレッジ)にはこのブログのすべての記事からテキストを抽出したデータとモノづくり塾の所在地や私のプロフィールなど … 続きを読む

前回の投稿「AI時代の失業問題」を生成AIの助けを借りて論文調に書き換えてみました。 正直なところ、私は文章を作るのが下手です。話すのもあまり得意ではありません。なので、この書き換えた文章の良否を判断する能力が足りないと … 続きを読む
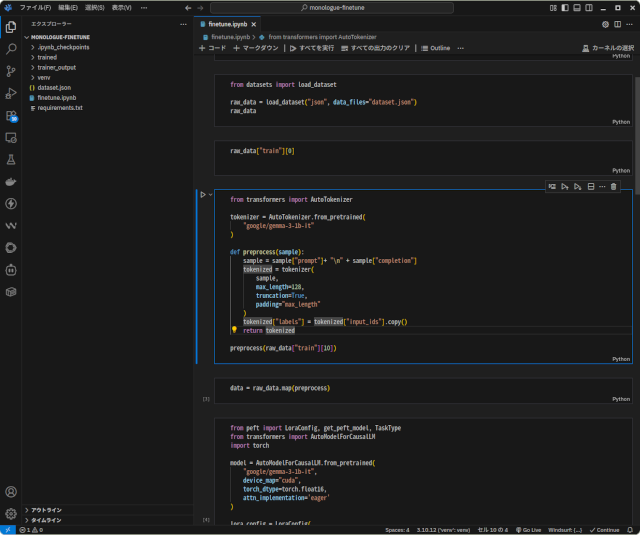
先日、このブログをクローリングして投稿を機械学習用のデータセットに変換するプログラムを書きました。今回はその続きで、そのデータセットを使った既存の学習済言語モデル(Pretreined Language Model)をL … 続きを読む

モノづくり塾での活動から知識を蓄積して公開する方法を研究しています。例えば、 というようなことを漠然と考えています。 このブログのように日々の活動や思考を記録をしているのは、3の知識集積を意識していますが、塾生も含めた全 … 続きを読む
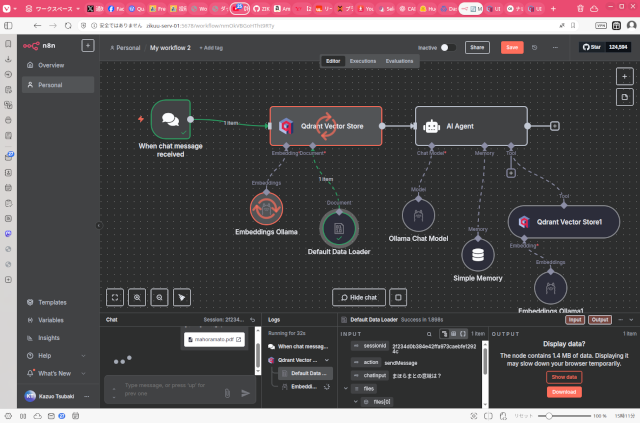
Ollama、Qdrant、n8nの組み合わせで簡単なRAGアプリケーションを作ってみました。 初めての使用だったので調べながら作業して1時間くらいかかったと思います。ノーコードツールですので、非プログラマーの方でも十分 … 続きを読む
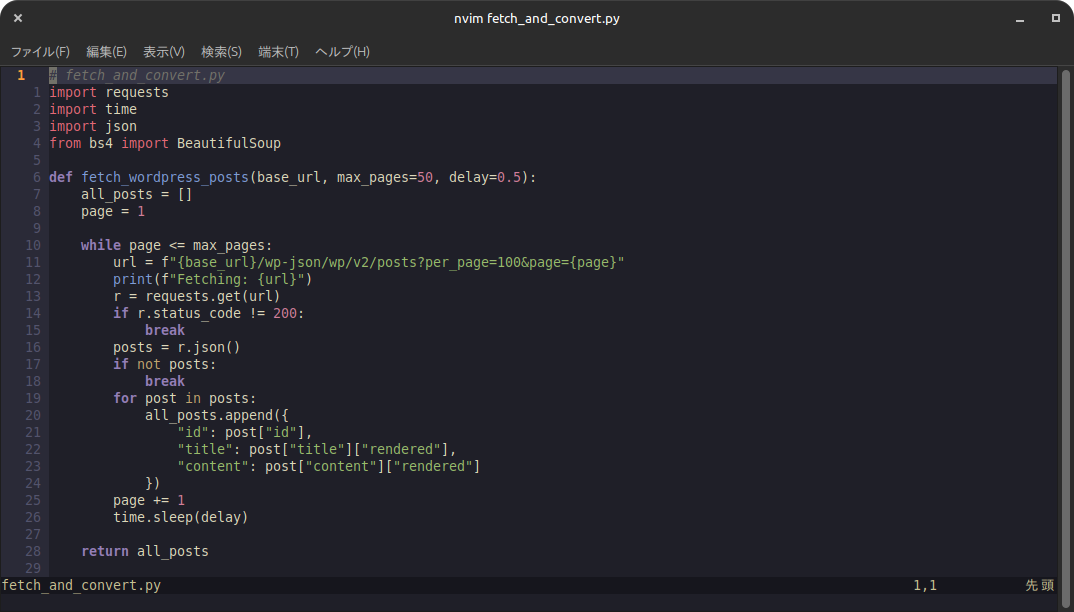
前回はこのブログの記事をすべて取得するプログラムと取得した記事からデータセットを作成するプログラムが別でしたが、それらを1つのプログラムにまとめたのが以下です。 近々、小さめのLLMでファインチューニングをしてみようと思 … 続きを読む
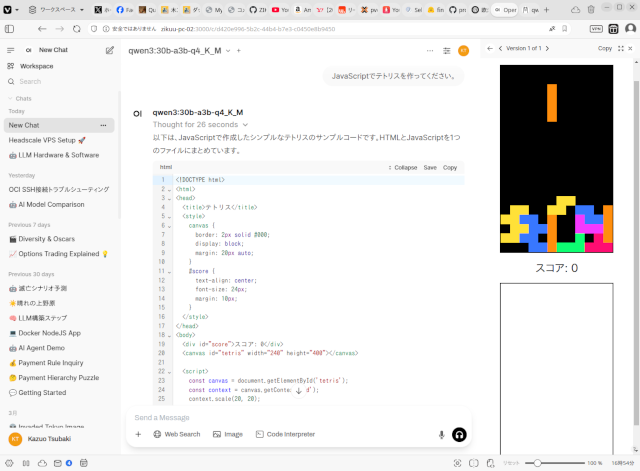
中国製の大規模言語モデルQwen3が公開されたのでローカルPCのOllamaで動かしてみました。 30BのMoE (Mixture of Expert)を4ビット量子化したもの、14Bの4ビット量子化したもの、4Bの3つ … 続きを読む