モノづくり塾は何かを新たに学ぶ動機付けや始める際の敷居を下げることを重視して運営しています。現在用意している5つの体験教室もその流れで考えたものです。
今回は、手元のPCで動く大規模言語モデルを利用した文書生成WebアプリケーションをPythonで実装し、Dockerで運用するというものを紹介します。こういうのをやってみて面白いと思ってもらえると嬉しいです。
開発環境はLinux (Linux Mint)ですので、それ以外の環境をお使いの場合は適宜読み替えてください。
使用するライブラリーはLangChainとLlama-cpp-pythonです。Web UIを作るのにStreamLitを使います。
では、はじめます!
プログラムを作成するPythonの仮想環境を作る
ターミナルを開いて適当な場所にプロジェクトフォルダーを作り、そのフォルダーの中で次のコマンドを実行します。
python -m venv llama_cppこれはllama_cppという名前のPython仮想環境を作るコマンドです。
Python仮想環境を有効化する
source llama_cpp/bin/activate必要なライブラリーをインストールする
プロジェクトフォルダーにrequirements.txtというテキストファイルを作り、次の内容に編集して保存します。
langchain
langchain-community
llama-cpp-python
streamlitllama-cpp-pythonはダウンロードされた後にコンパイルされます。コンパイルに必要なライブラリが必要なので次のコマンドでライブラリんをインストールしておきます。
sudo apt install build-essentialpipコマンドを使ってライブラリーをインストールします。
pip install -r requirements.txt言語モデルをダウンロードする
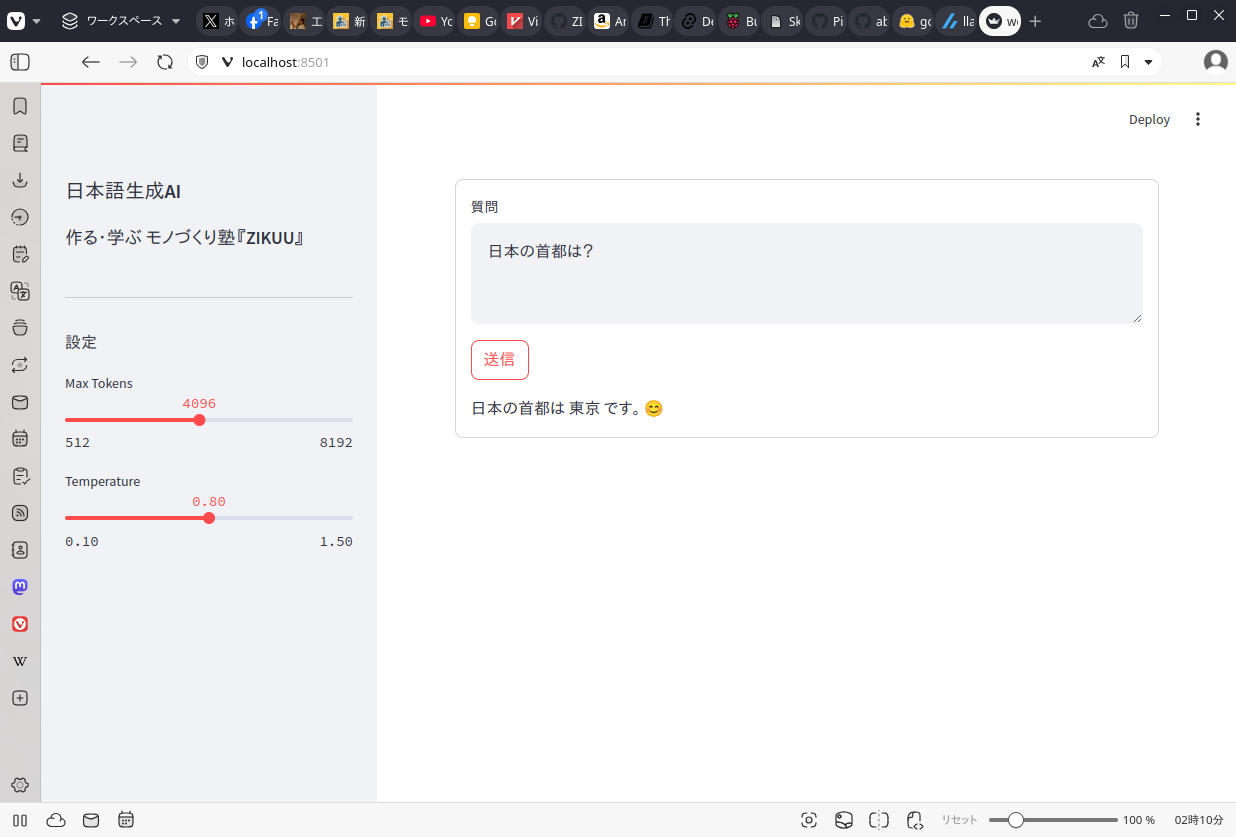
プロジェクトフォルダーにmodelsというフォルダーを作り、その中に言語モデルをダウンロードして保存します。今回は20億パラメーターのGemma2を量子化したものを使用しました。
次のコマンドで言語モデルをダウンロードします。2GBほどのサイズなのでダウンロードが終了するまでに時間がかかります。
mkdir models
wget -P ./models https://huggingface.co/bartowski/gemma-2-2b-it-GGUF/resolve/main/gemma-2-2b-it-Q6_K.ggufwgetがインストールされていない場合は次のコマンドでインストールして、ダウンロードをやり直してください。
sudo apt update
sudo apt install wgetこの段階でプロジェクトフォルダーは次のようになっている筈です。
最も単純なプログラム
Pythonで言語モデルを使って文章生成を行う簡単なプログラムを作って、正しく処理ができることを確認します。
main.pyを次の内容で作ります。
from llama_cpp import Llama
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人アシスタントです。質問に対して日本語で丁寧に回答してください。"
def make_prompt(message):
prompt = "<bos><start_of_turn>user {system} {prompt} <end_of_turn> <start_of_turn>model".format(system=DEFAULT_SYSTEM_PROMPT, prompt=message)
return prompt
llm = Llama(
model_path="./models/gemma-2-2b-it-Q6_K.gguf",
n_ctx=4096,
)
output = llm(make_prompt("Name the planets in the solar system?. "),
max_tokens=4096,
echo=True
)
print(output)
main.pyを実行します。
python main.py次のような出力が得られれば正常に動作しています。(太陽系の惑星の名前を質問し、少し変ですが、それらしい回答が得られます)
llama_model_loader: loaded meta data with 39 key-value pairs and 288 tensors from ./models/gemma-2-2b-it-Q6_K.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = gemma2
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Gemma 2 2b It
llama_model_loader: - kv 3: general.finetune str = it
llama_model_loader: - kv 4: general.basename str = gemma-2
llama_model_loader: - kv 5: general.size_label str = 2B
llama_model_loader: - kv 6: general.license str = gemma
llama_model_loader: - kv 7: general.tags arr[str,2] = ["conversational", "text-generation"]
llama_model_loader: - kv 8: gemma2.context_length u32 = 8192
llama_model_loader: - kv 9: gemma2.embedding_length u32 = 2304
....
....
....
....
llama_perf_context_print: load time = 1265.40 ms
llama_perf_context_print: prompt eval time = 0.00 ms / 38 tokens ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: eval time = 0.00 ms / 93 runs ( 0.00 ms per token, inf tokens per second)
llama_perf_context_print: total time = 10987.63 ms / 131 tokens
{'id': 'cmpl-ea481b2d-bee9-4158-8b9b-77e435daee45', 'object': 'text_completion', 'created': 1737046849, 'model': './models/gemma-2-2b-it-Q6_K.gguf', 'choices': [{'text': '<bos><start_of_turn>user あなたは誠実で優秀な日本人アシスタントです。質問に対して日本語で丁寧に回答してください。 Name the planets in the solar system?. <end_of_turn> <start_of_turn>model 太陽系には、太陽を中心に回る惑星が、以下の通りです。\n\n1. **Mercury:** 金星\n2. **Venus:** 土星\n3. **Earth:** 地球\n4. **Mars:** 火星\n5. **Jupiter:** 木星\n6. **Saturn:** 金星\n7. **Uranus:** 天王星\n8. **Neptune:** 海王星 \n\n\n \n \n', 'index': 0, 'logprobs': None, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': 38, 'completion_tokens': 93, 'total_tokens': 131}}
この短いプログラムが言語モデルを扱うプログラムの起点になります。
Web UIを作る
WebフレームワークのStreamLitを使ってWebブラウザからアクセスできるプログラムを作ります。
web.pyという名前のファイルを作り、次の内容に編集して保存します。
import streamlit as st
from langchain.callbacks.base import BaseCallbackManager
from langchain_community.llms import LlamaCpp
from langchain.callbacks.base import BaseCallbackHandler
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人アシスタントです。質問に対して日本語で丁寧に回答してください。"
model_path = "./models/gemma-2-2b-it-Q6_K.gguf"
class StreamHandler(BaseCallbackHandler):
def __init__(self, container, initial_text="", display_method="markdown"):
self.container = container
self.text = initial_text
self.display_method = display_method
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.text += token
display_function = getattr(self.container, self.display_method, None)
if display_function is not None:
display_function(self.text)
else:
raise ValueError(f"Invalid display_method: {self.display_method}")
def make_prompt(message):
prompt = "<start_of_turn>user {system} {prompt} <end_of_turn> <start_of_turn>model".format(system=DEFAULT_SYSTEM_PROMPT, prompt=message)
return prompt
with st.sidebar:
st.header('日本語生成AI')
st.subheader('作る・学ぶ モノづくり塾『ZIKUU』')
st.divider()
st.text("設定")
max_tokens = st.slider('Max Tokens', value=40960, min_value=8192, max_value=81920, step=32)
temperature = st.slider('Temperature', value=0.8, min_value=0.1, max_value=1.5, step=0.05)
n_ctx = st.slider("Number of Ctx", value=8192, min_value=64, max_value=8192, step=1)
n_batch = st.slider("Number of Batch", value=128, min_value=1, max_value=8192, step=1)
with st.form(key="generation_form"):
prompt = st.text_area('質問')
do_generate = st.form_submit_button('送信')
if do_generate and prompt:
with st.spinner("生成中..."):
chat_box = st.empty()
stream_handler = StreamHandler(chat_box, display_method='write')
chat = LlamaCpp(
model_path=model_path,
temperature=temperature,
max_tokens=max_tokens,
n_ctx=n_ctx,
n_batch=n_batch,
callback_manager=BaseCallbackManager([stream_handler]),
verbose=False,
)
res = chat.invoke(make_prompt(prompt))
次のコマンドでプログラムを起動します。
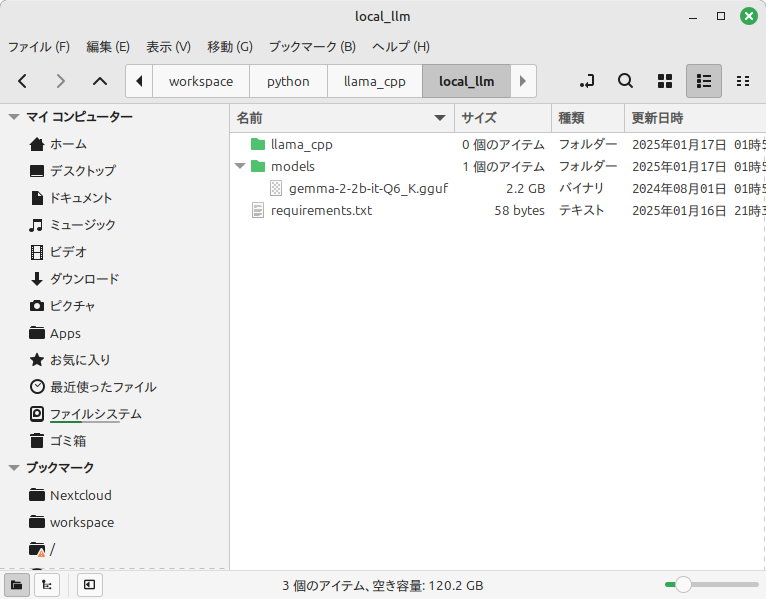
streamlit run web.pyWebブラウザから http://localhost:8501にアクセスすると、次のような画面が表示され、質問欄に何かを入力して送信ボタンを押すと生成された文章が表示されれば成功です。
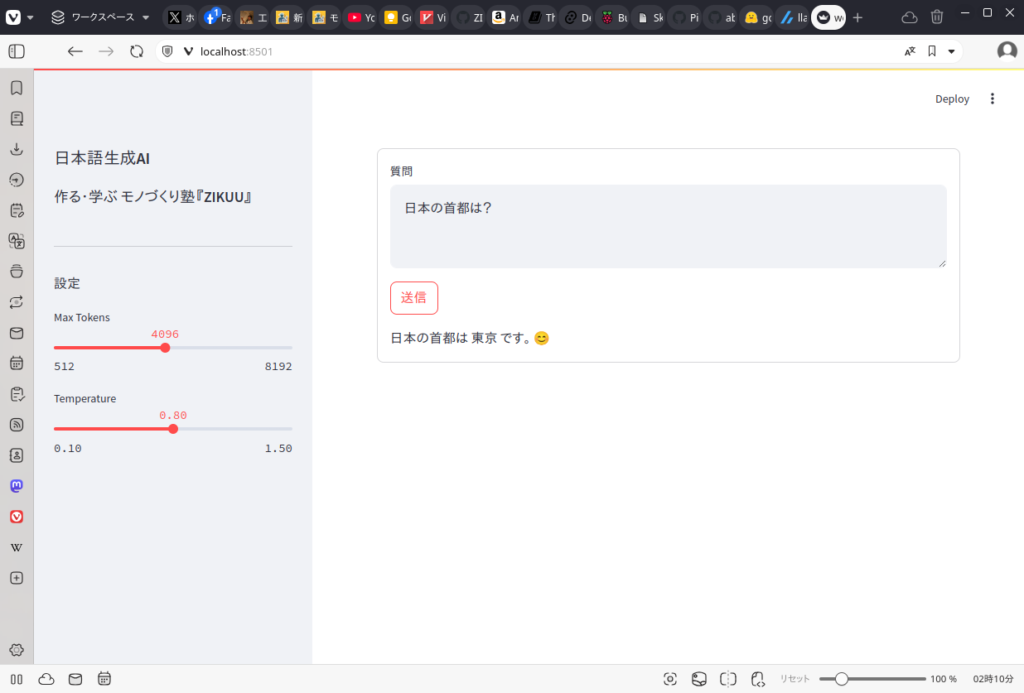
これで生成AIを扱うWebアプリケーションを作るという目的まで達成できました。
Dockerでプログラムを動かす
DockerはOSの上に仮想のOS環境を作りアプリケーションを運用するためのツールです。作成したアプリケーションをDockerで動かせるようにしておくと、サーバーにアプリケーションをインストールしたり、他の人とプロジェクトを共有するのが容易です。
Dockerがインストールされていない場合は、モノづくり塾のプログラマー向けセットアップを参考にしてインストールしておいてください。
まずはプロジェクトフォルダーのdockerフォルダーを作り、その中に移動します。
mkdir docker
cd dockerDockerfileという名前のテキストをファイルを次の内容で作ります。(説明のために行番号を振っていますが、実際に作成するファイルには行番号は不要です)
1: FROM ubuntu:22.04
2:
3: ENV DEBIAN_FRONTEND=noninteractive
4: ENV DEBCONF_NOWARNINGS=yes
5:
6: RUN apt-get update && apt-get upgrade -y
7: RUN apt-get dist-upgrade -y && apt-get autoremove -y
8: RUN apt-get install -y build-essential wget
9: RUN apt-get install -y python3 python3-venv
10:
11: WORKDIR /app
12:
13: RUN wget -P ./models https://huggingface.co/bartowski/gemma-2-2b-it-GGUF/resolve/main/gemma-2-2b-it-Q6_K.gguf
14:
15: COPY ./requirements.txt /app
16: COPY ./web.py /app
17:
18: RUN python3 -m venv /llama_cpp
19: RUN . /llama_cpp/bin/activate && python -m pip install --upgrade pip
20: RUN . /llama_cpp/bin/activate && python -m pip install -r requirements.txt
21:
22: COPY ./docker/entrypoint.sh /
23: RUN chmod 755 /entrypoint.sh
24:
25: EXPOSE 8501
26: ENTRYPOINT ["/entrypoint.sh"]この内容について簡単に説明します。
- 1行目:Ubuntu 22.04をベースOSとして使用する
- 6行目:ベースOSの更新や必要なライブラリーのインストール
- 11行目:ワークディレクトリの設定
- 13行目:言語モデルのダウンロード
- 14行目:ソースコードなどをワークディレクトリにコピー
- 18行目:Python仮想環境の作成
- 20行目:Pythonライブラリのインストール
- 22行目:entrypointファイル(プログラムの実行開始コマンド)のコピー
- 23行目:entrypointファイルへの実行権の付与
- 25行目:アクセスするネットワークポートの公開(Streamlitのデフォルトポートです)
- 26行目:entrypointの指定
次にdocker-compose.ymlという名前のDockerデプロイファイル(Docker composeファイル)を作ります。
version: '3.8'
services:
app:
build:
context: .
dockerfile: ./docker/Dockerfile
network: host
ports:
- "8501:8501"この段階でプロジェクトフォルダーは次のようになっている筈です。
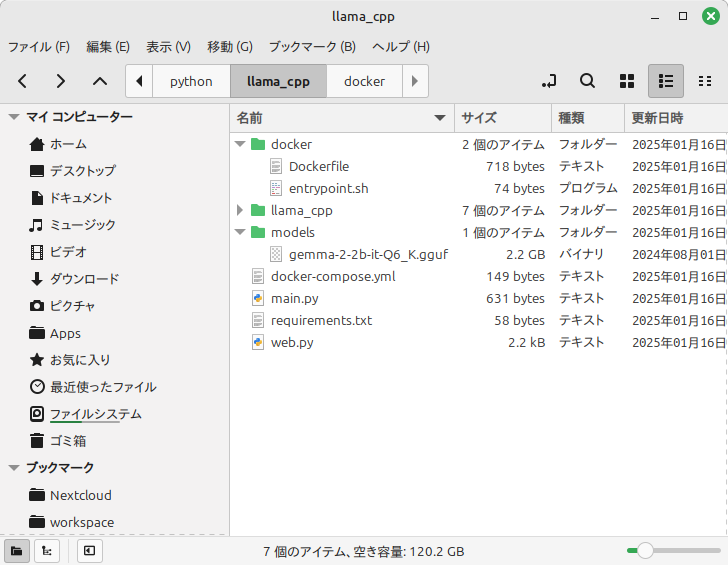
これでDockerでアプリケーションを動かす準備が整いました。
次のコマンドでアプリケーションを起動します。(1回目の起動時は言語モデルやライブラリのインストールに時間がかかります)
docker compose upWebブラウザーで http://localhost:8501 を開くと、先程と同じ画面が表示されれば成功です。
このDockerを使う方法ならば、サーバーにPythonライブラリなどをいちいちインストールしなくてもアプリケーションをインストール・実行ができますし、開発用のPCとサーバーとのOSの違いを意識しなくて済みます。
実際の開発・運用の現場では、プロジェクトをGithubやGitlabなどのリポジトリに登録しておき、サーバーでリポジトリからプロジェクトをダウンロードして、docker compose upコマンドでアプリケーションを起動するといった方法を取ります。大規模なシステムではサーバーがクラスター化されるなどの要素が加わりますが、基本的な開発から運用までの手順はだいたいこのような形です。(CI/CD – Continuous Integration/Continuous Development = 継続的な運用と開発、と呼ばれるものです)
大規模言語モデルを使った簡単なアプケーションを開発して動かすという流れを解説しました。ここから先には、言語モデルをチューニングする、アプリケーションに機能を追加する、自分で言語モデルを開発する、他のプログラミング言語でアプリケーションを実装する、大規模なサーバーを構築するなど、学ぶテーマがたくさんあります。
今回の内容は真似すれば出来そうな気がしませんか?
最初は真似で良いのです。真似でも良いから成果を出して、動くことに喜びを感じ、興味が深まればその先に進めば良いのです。
