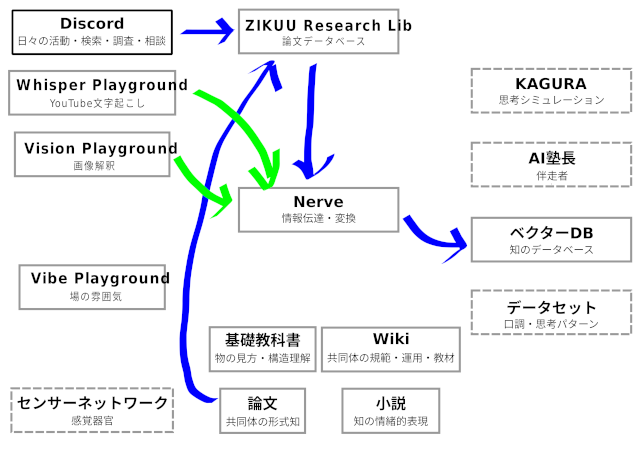
昨日の時点で、Discord→ZIKUU Research Library→Nerve→Qdrant(ベクターDB)という流れを組めました。
これでネット検索した論文やZIKUU内部で書かれた論文が、AIが参照できるデータとして保存されるようになりました。
今日は、語彙(ZIKUU Vocabulary)用のパイプラインを作りました。
この語彙は、ZIKUU内のGiteaリポジトリに置かれており、エントリを更新してプッシュすると、バックグラウンドで自動的にパイプラインが動いて、ベクターDBにデータを追加・更新をしてくれます。
この語彙は、共同体の精神とも呼べるものです。
この部分を独自の精神に置き換えることで、AIの動作を共同体に合わせることができます。
ZIKUU専用設計ではありません。
この語彙は、ベクターDBに入ると同時に、後々、LLMのファインチューニング用のデータとして使われます。これで共同体の文化・癖みたいなものをLLMが身につけることになります。
上の図の青矢印の部分が入力データがベクターDBまで流れるパイプラインです。
緑矢印の部分は、Nerveに投げ込むところまで完成しています。
AI塾長は、語彙(精神)→論文など(知識)の順にベクターDBを検索し、共同体にあった応答をします。
語彙と論文の入れ物ができたので、AI塾長の文書生成実験に取りかかれます。
そこまでが綺麗に動けば、あとは、パイプラインを増やして、上の図の矢印が引かれていない部分を埋めていくだけです。
