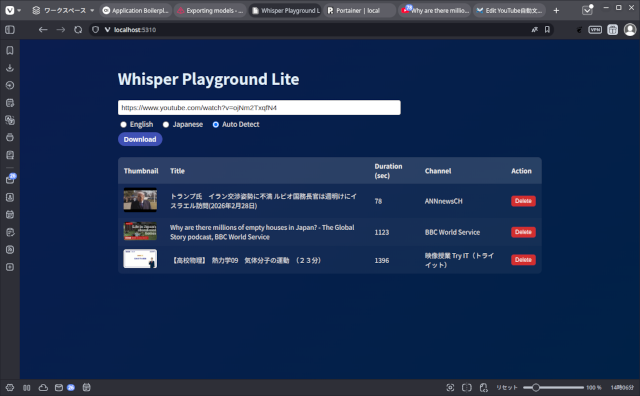
すでにWhisper PlaygroundというYouTube動画から文字起こしするアプリケーションを開発していますが、その軽量版をローカルLLMを助手にして開発していました。
アプリケーション概要
yt-dlpでダウンロードしたYouTube動画の音声をfaster-whisperで文字起こしするWebアプリケーションです。
Docker Composeで起動する、React+ViteのフロントエンドとFastAPIのバックエンドという構成。
開発は、ボイラープレート生成、バックエンドの開発、フロントエンドの開発と進めます。
プロジェクト用のフォルダーをOpen WebUIで作り、フォルダーのシステムプロントを開発用のものに設定してから、開発に入ります。
開発の要点
- 一度、多くの実装をせずに小さく進める。
- 設計と実装の方針を示して、LLMにコード生成をさせ、都度、コードをざっくり確認してから次へ。
- 必要だと思ったら、検証用のコマンドを作らせて動作確認する。
- 使用する機材に依存するが、一般に、ローカルLLMではコンテクストウィンドウが小さいために、プロジェクト全体をLLMが把握するのが困難なので、決して、丸投げはしないこと。
- 何を追加するか、どこを修正するかを、的確に指示するのが重要。
使用するモデルはgpt-oss:20bの量子化版。それをOllamaで動かします。
使用機材は、RTX 2000 Ada世代でVRAMは16GBのGPUと、13世代Core i5を搭載したUbuntuマシンで、それにリモートアクセスして作業を進めます。
前提スキル
- Webアプリケーション開発経験あり。
- ReactとFastAPIに関する知識。
- Docker及びDocker Composeに関する知識。
- Gitに関する知識。
さすがに経験ゼロというわけにはいきません。
出来上がったアプリケーション
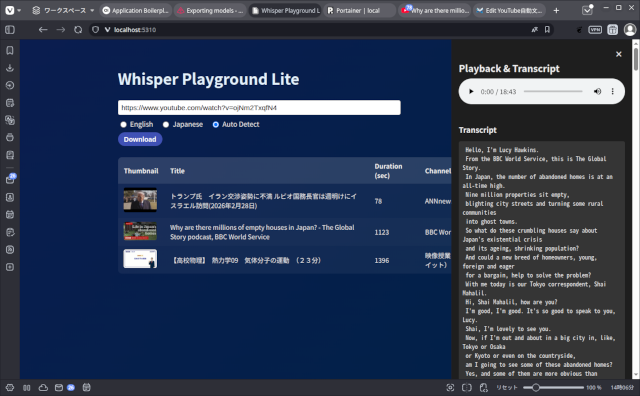
完成までの所要時間は8時間くらい。
あまり速くはありません。
途中何度か、手元でコードを修正し、それを渡して書き直しさせるなどしています。
使用する技術が既知のものばかりなら、LLMを使わなくてもこの程度の時間で作れると思いますが、私の場合は、Fast API、React、yt-dlp、faster-whisperについては、中途半端な知識しかありませんから、LLMを使わなかったら2倍から3倍の時間がかかるかもしれません。
このタイプの作業では、LLMにコンテクストを渡すところにパワーが必要です。大きくて速いメモリが欲しくなる。
もっと大きなサーバーで、コード生成能力の高いLLMをローカルで走らせられたら、数人規模の開発会社なら、ローカルLLMを使ったアプリケーション開発は現実的な選択肢だと思います。
今回使った、gpt-oss:20bのコンテクスト長は128Kとされていますが、これくらいの小さなアプリケーションでは問題にはなりませんが、大きなプロジェクトになったら、プログラムの構造把握ができなくなって破綻するかもしれません。また、1人で専有しても、容量的にも速度的にもVRAM 16GBのRTX 2000 Adaには少し荷が重い。RTX 3090 辺りを使えば、快適に開発を進められるでしょう。

「ローカルLLMを使ってWebアプリケーションを開発する」への1件のフィードバック