運用を開始してそろそろ1ヶ月。
日々データが更新されており、国際ニュースを収集して作ったFactデータが40000件ほど蓄積されています。
ZIKUUでは、日々の活動や外部情報を、あとから考え直せる形で蓄積するシステムを作っています。
この後、Context Pipeline Serverという、データから文脈束を抽出してPivot用のFactに変換するアプリケーションを開発し、Pivotサービスの中で、ブログやDiscordの活動履歴、ラジオ放送、基礎教科書や小説などから取り出した文脈をFactデータベース化します。
ZIKUUが内部に蓄積するのは、生データ(Archive)、そこから抽出した文脈束(Context Bundle)、文脈束を構造化した意味空間(FactとDimension)です。これ全体で知識空間ができます。それが共同体の記憶になる。
PRE (Pivot Reasoning Engine)は、Fact+Dimension→Context Bundle→Archiveを往復しながら、文脈から立ち上がる意味を見つけることになります。それを人とAI塾長が操作する形が完成形です。
ちなにみ、私は30年ほど前から、Contextual Computingという概念がなんとなく頭の中にあって、「意味は文脈から浮かび上がる」という考え方を持っていました。Semanticを扱おうという流れがありますが、SemanticはContextから立ち上がると考えると、Semanticの先の話をしているわけです。Semantic Webの次のContextual Webみたいな世界の話。
実はもっと先のプランもあるのですが、30年の月日を経て、PRE+AI塾長という形で、文脈を扱うシステムが一応の完成を見ることになります。当時はロマンでしたが、それが現実になりつつあります。
今日は、Context Pipeline Serverを開発する前にPivotサービスに対してやっておきたいことをやりました。
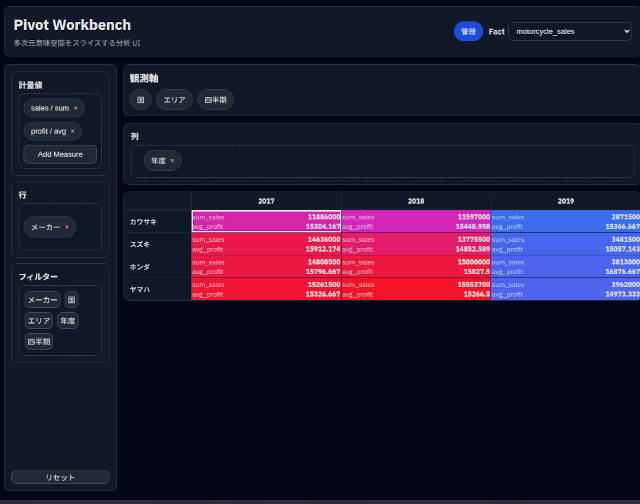
まずは、Measure(集計値)の多値化。
これまでは表示できる値は一つでしたが、複数の値を表示できるようにしました。
これは売上の合計と利益の平均を表示している様子です。
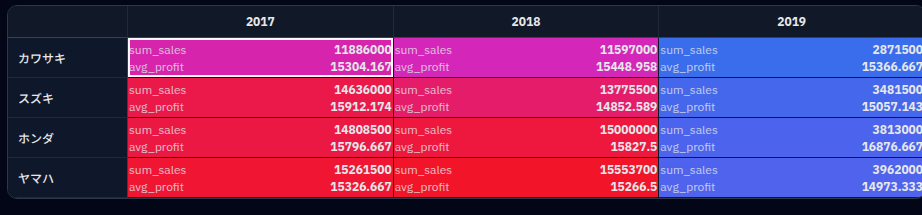
元データはこうなっています。(Fact1件について)
measuresにsales: 1330000、profit: 18300と表示されています。
これらの合計、平均、最大、最小を、好きなだけ表に出せます。
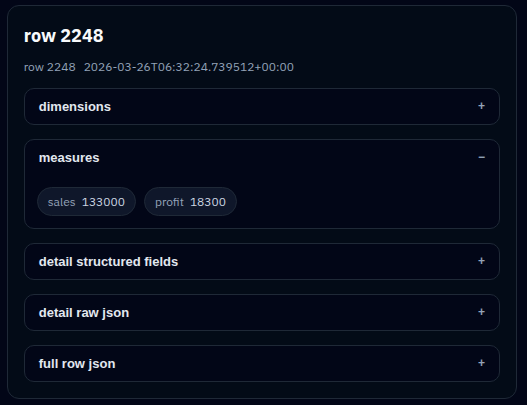
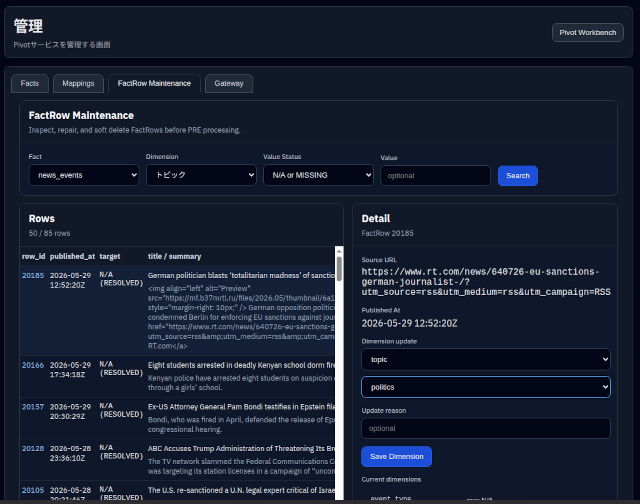
もう一つの拡張は、Dimension抽出に失敗したFact行への対応で、Dimension(何らかの理由で抽出に失敗した場合)の付け直しとFact行の削除(無意味なデータの場合)をする機能です。
例えば、国際ニュースFactの場合に、何らかの理由でDimension抽出に失敗してN/AやUnknownになっているデータがあります。これらは無効なデータで、現時点で全体の0.8%でした。
傾向を見るだけなら無視する手もありますが、数が少ない=意味が薄いではないので、できるだけ意味を拾いたい。ZIKUUのAIシステムは、事実を辿るシステムなので、Fact(事実)をないがしろにはできません。
管理画面にFactRow Maintenance画面を追加して、Dimensionの振り直し、無効なデータの削除ができるようにしています。
これでContext Pipeline Serverの開発に進めます。
その後、PRE、AI塾長と開発して完成。
たぶん、途中に小さなツールをいくつか作ることになるので、そんなに速く完成しないと思いますが、順調に進んでいるのは確かです。
30年考え続けてきたこと。
今になって整理してみると、ギターを作り始めたこと、ロードバイクを作り始めたこと、ZIKUUを始めたこと、Pivotを作り始めたことのすべてが同じ考えの上のことだったと気づきます。形は違うものの、その背後にある文脈はすべて同じだった、みたいな発見がありました。
続けること。
これはとても大事。

「Pivotサービスの機能拡張」への1件のフィードバック