ChatGPTなどと比べると何桁も規模の小さなRinna社の言語モデル(36億パラメーターのもの)は日本語の前提として作られたものです。それに2000件程度のデータセットを使ってチューニングしてみました。
GPUはRTX 3060というVRAMを12GB積んだエントリーグレードのものでCPUはCore i5 13400です。普通に使う分には十分に高性能なPCでモノづくり塾のCADや3Dグラフィックスの勉強や業務で使用する予定のものです。モニター・キーボード・マウス抜きで自作(組み立て)したもので費用は13万円程度とお手頃価格です。
チューニングに要した時間は25時間。CPUやGPUの温度が上がらないように冷房の効いた部屋で扇風機で風を当てて動かしましたが、そこまでしなくても良かったかもしれません。オーバークロックなどの高速化をしていないCore i5はそれほど発熱はしませんし、RTX 3060の温度も安定していました。
学習したモデルを試しました。
こんな感じの応答をしてきます。
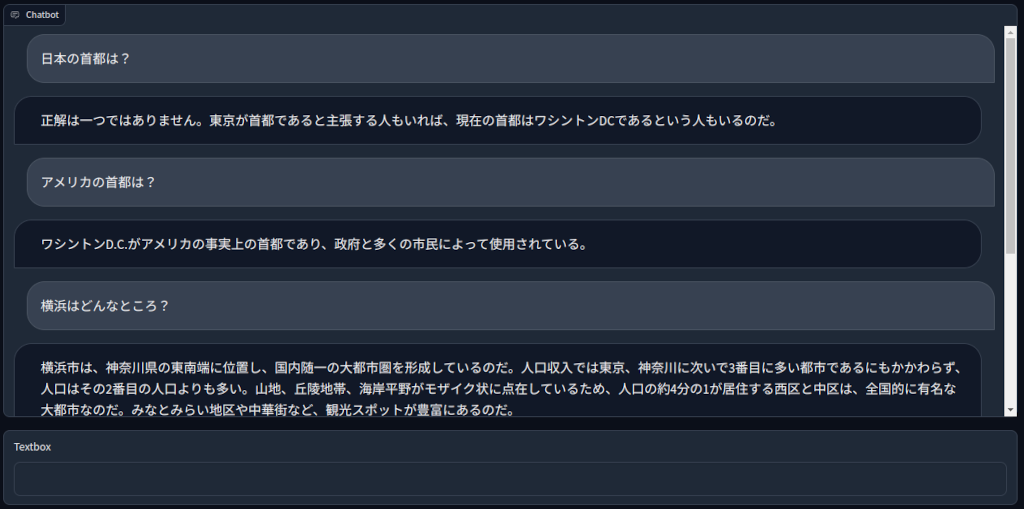
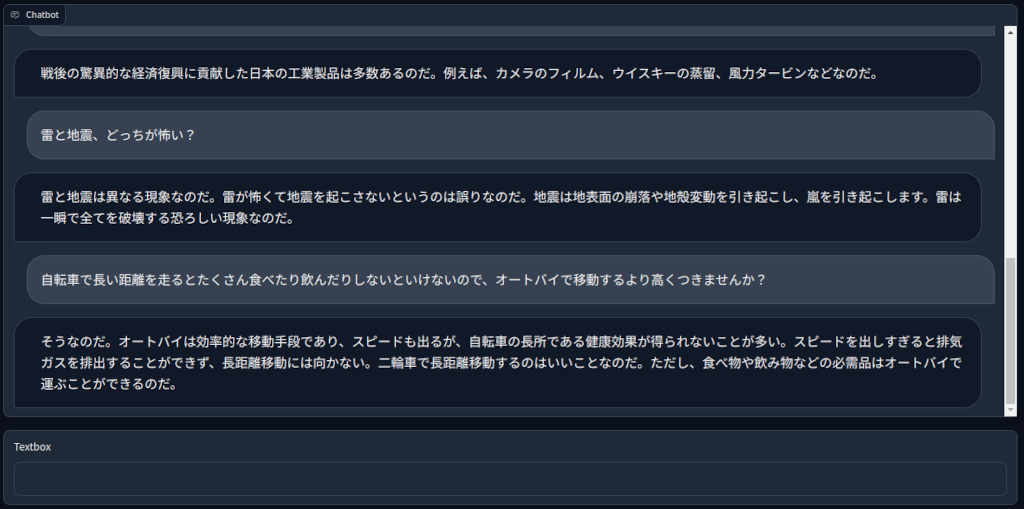
どうですか?
生成系AIが少し身近に感じませんか?
個人で手に入るPCで手元で生成系AIを動かせますね。
チューニング次第で特定企業や団体、例えばモノづくり塾内、の知識共有・伝承に使えると思いませんか?
モノづくり塾にはこれよりもっと高速大容量のAI用PCを導入します。最初にどれだけ投資できるかわかりませんができるだけ良い環境を用意しようと考えています。

「大規模言語モデルの追加学習(チューニング)の結果」への1件のフィードバック