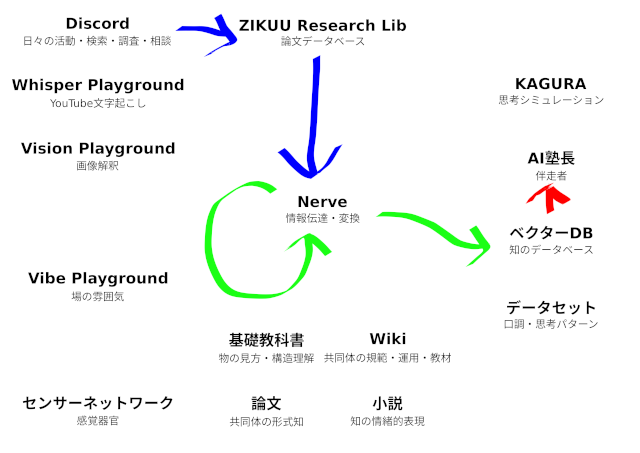
今日は、検索した論文の要約を生成してQdrantに投げ込む処理(上の図の緑色矢印の部分)を実装しました。「論文処理用のNerveパイプラインを開発する」という投稿の続きです。
実際の運用では、
① Discordの専用チャンネルで論文を検索
↓
② ボットが検索したデータをGiteaにプッシュ(データソース)
↓
③ Git Actionsが保存された論文データをイベントに変換してNerveに送信(Ingest行程)
↓
④ Nerveは要約パイプラインにデータを送信(イベント配信行程)
↓
⑤ 要約パイプラインがLLMを使って要約(Pipeline行程)
↓
⑥ Qdrantに保存(最終処理)
が自動化されます。
概念的には、この流れ全体をパイプラインと呼んでいますが、プログラムコンポーネント的には⑤がパイプラインです。
①から⑤まで流れているデータは人間が読むもの、⑥はAIが読むもの。
人が介在するのは①だけ。
①、②の代わりに、人が論文データをGiteaにプッシュしても、③以降は自動的に流れる。
例えば、Giteaリポジトリに新エントリをプッシュすると・・・
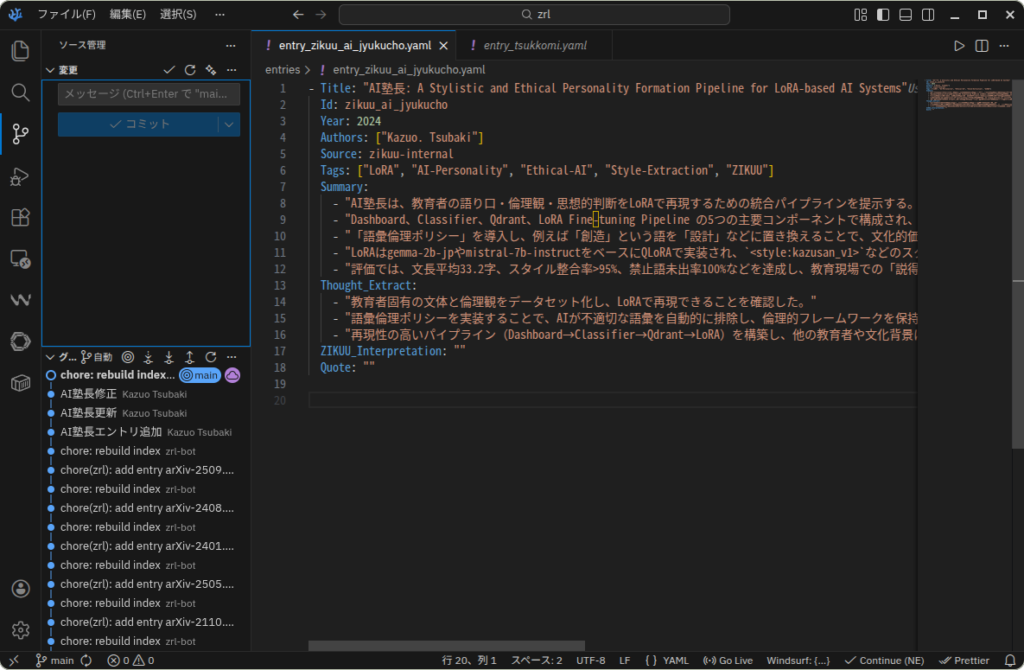
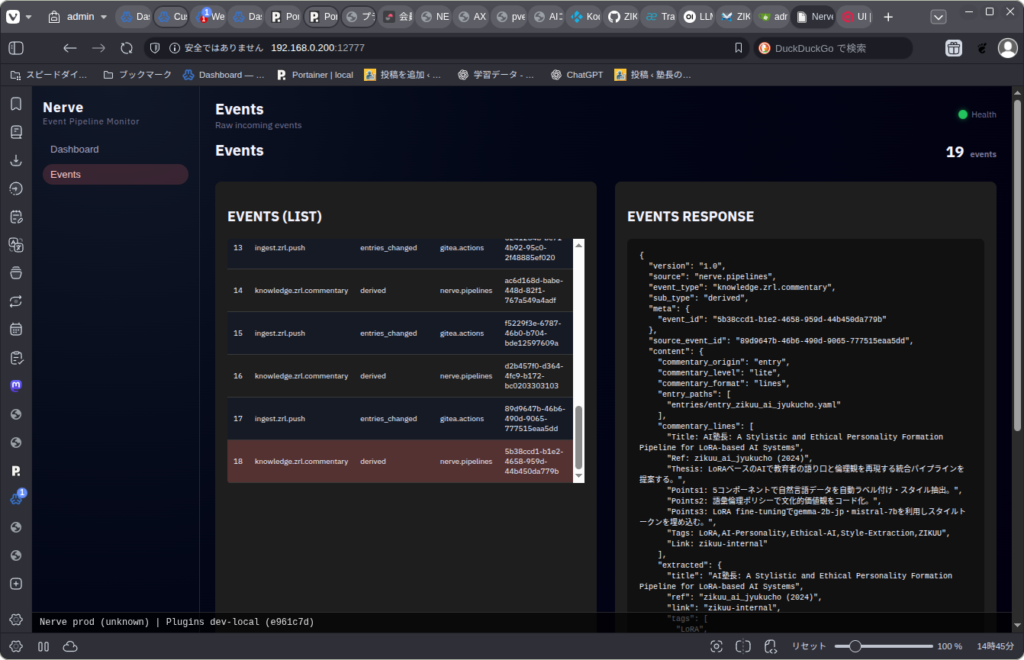
Git Actionsが走って、Nerveにイベント送信し・・・
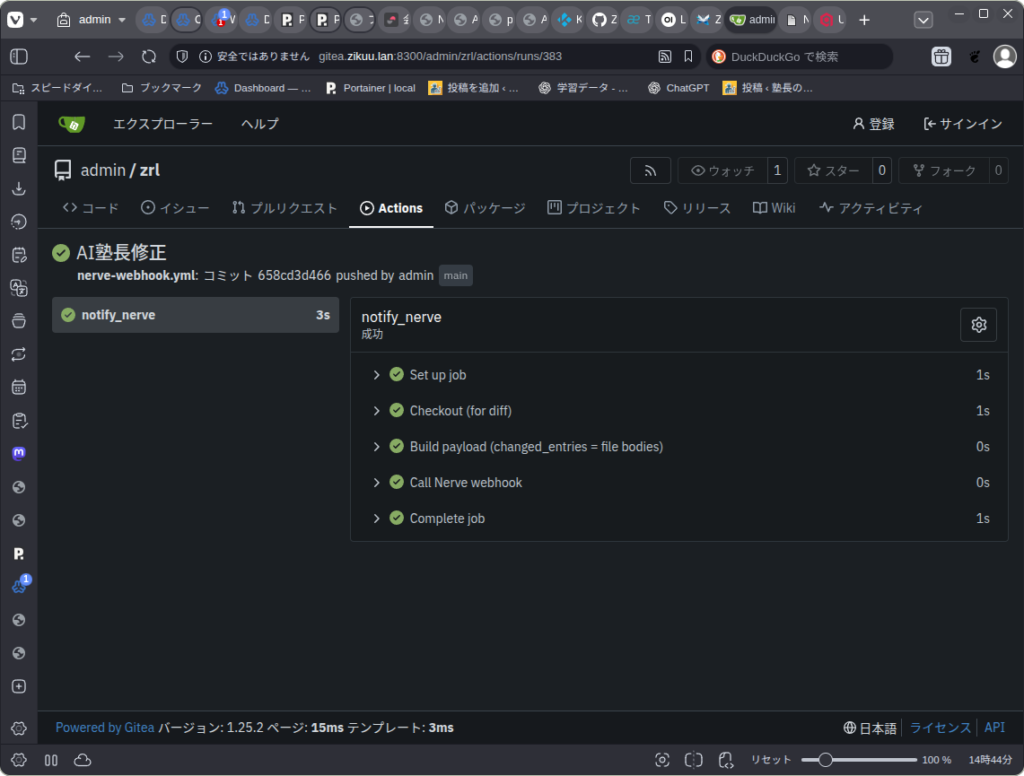
Nerveは届いたイベントを処理してから、要約イベントを自分自身に投入し・・・
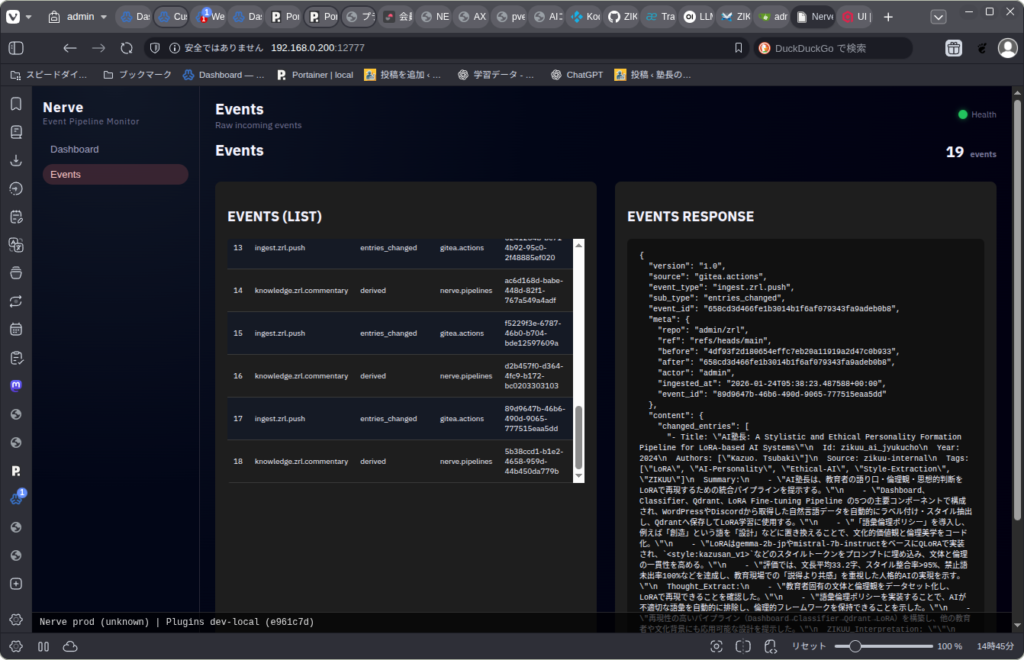
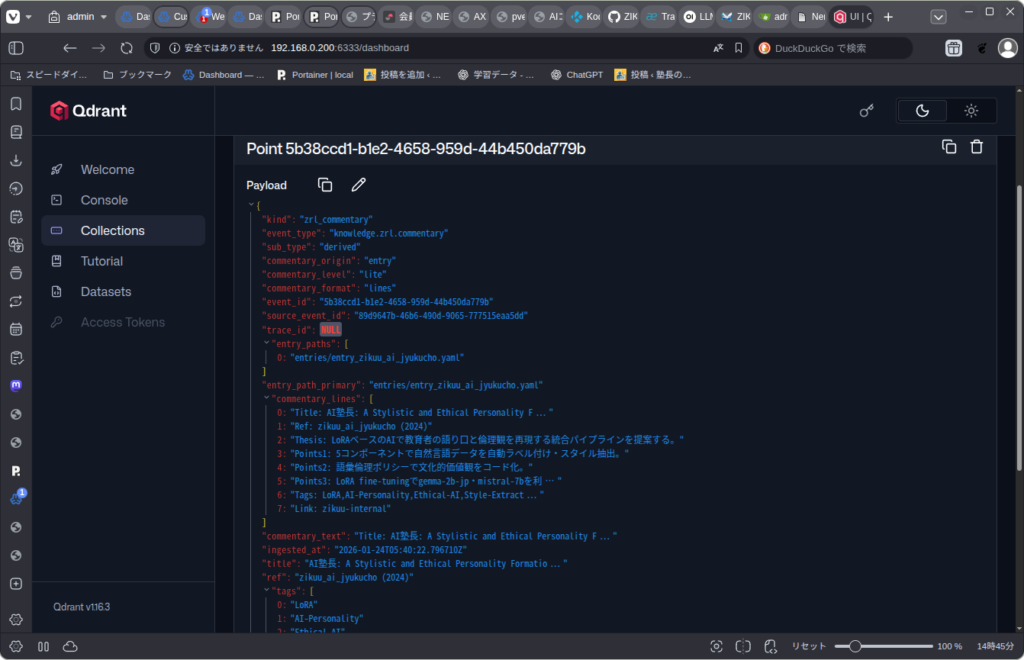
要約パイプラインが選択されて、LLMを使って要約したデータをQdrantに登録する。
Qdrantに登録されたデータがこれ。
凄く面倒なことをやっているように見えるかもしれませんが、
- パイプラインが分岐することもありえるから、イベントとパイプラインを1対多でマップできる
- どの処理から始まっても、次が自動的に実行されるようにする
- パイプラインを置き換えれば、ワークフローを変更できる
- 分岐ロジックを書かずに、変更・拡張できる
などの理由でこうしています。
日々の生産活動や学習の背後で、こういう多種多様なパイプラインが静かに動くのがZIKUU v1.0というシステム(生態系)です。即時性を要求しない処理がほとんどなので、特別に速くて強いGPUが要らないし、大きな言語モデルも要らない。gpt-oss:20bで十分。
性能、規模、投資を競うゲームに、ZIKUUは乗らない。
