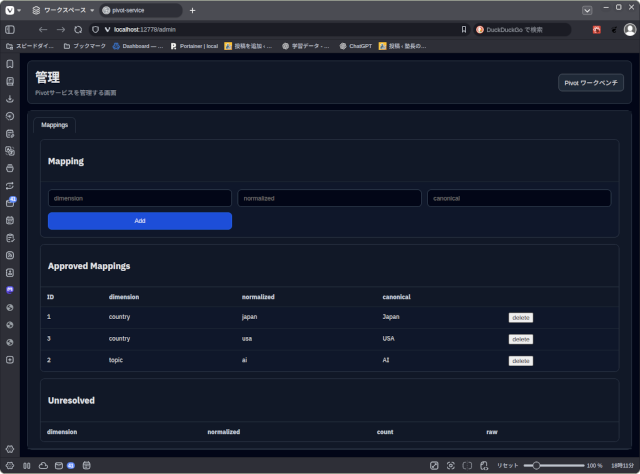
上の画面はPivotサービスの管理画面です。
このサービスは、
データを集める(ブログ、国際ニュース、国内ニュース、ラジオ、人工衛星、論文、活動記録など)
↓
LLMを使って、データから観測軸=Dimensionを抽出する(例:地域:東京、出来事:交通事故、発生日時:2026-03-21、天気:雨、みたいな)
↓
観測軸を名寄せ=Canonicalizeする
↓
Factデータとして保存する
という処理をしますが、一発でCanonizalizeできない場合に、対応表を育てながら、自動的に観測軸が整うようにしていきます。
上の画面が、その対応表を作る画面です。
AI塾長やWorld Eyeのようなアプリケーションは、このPivotサービスのFactをDimensionを動かしながら観察して意味を抽出します。
今日は、データモデルを整理して、試験的にデータを投入して、DimensionがCanonicalizeされる、というところまで開発が進みました。
次回は、本物のデータを大量投入して、Canonicalization処理の具合を見ます。
このシステムが完成すると、ZIKUUに蓄積されるデータは、すべて観測可能な意味空間に配置されることになります。
開発の傍らでは、文書の管理です。
ZIKUUでは、内部にGitHubのようなサービスを走らせており、そこに塾内で生成された、教科書、技術文書、論文などを管理しています。
日常の作業の中で、必要だと思ったことは、すぐに文書化して残すように心がけています。
今日はMarkdownとMermaidに関して文書をまとめました。
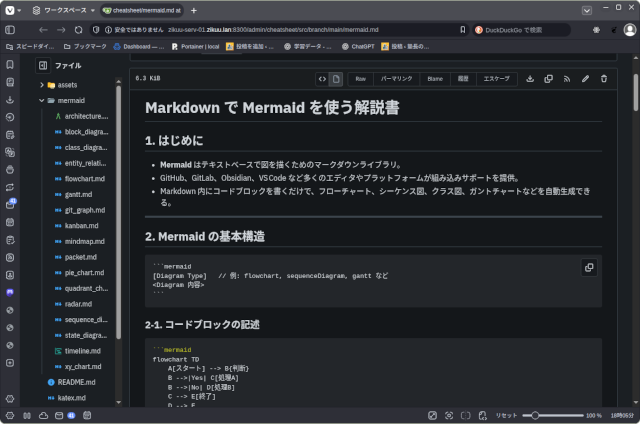
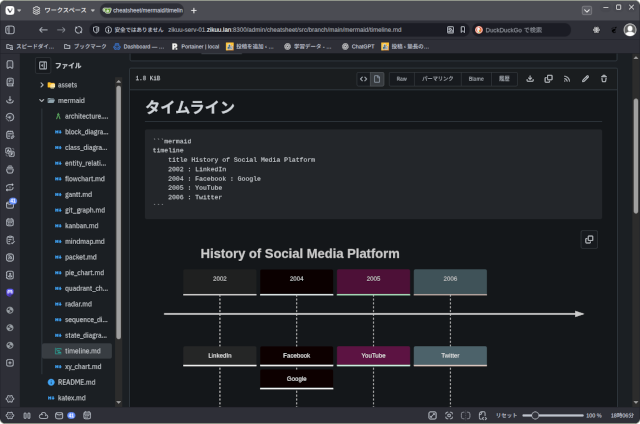
こういうものは、なかなか覚えていられないので、必要な時に、ZIKUUポータルから、1クリック2クリックでサッとみられるようにしておく必要があります。
AI塾長は、このような文書も参照するので、AI塾長が相談相手になってくれます。

「Pivotサービスの拡張を進める」への1件のフィードバック