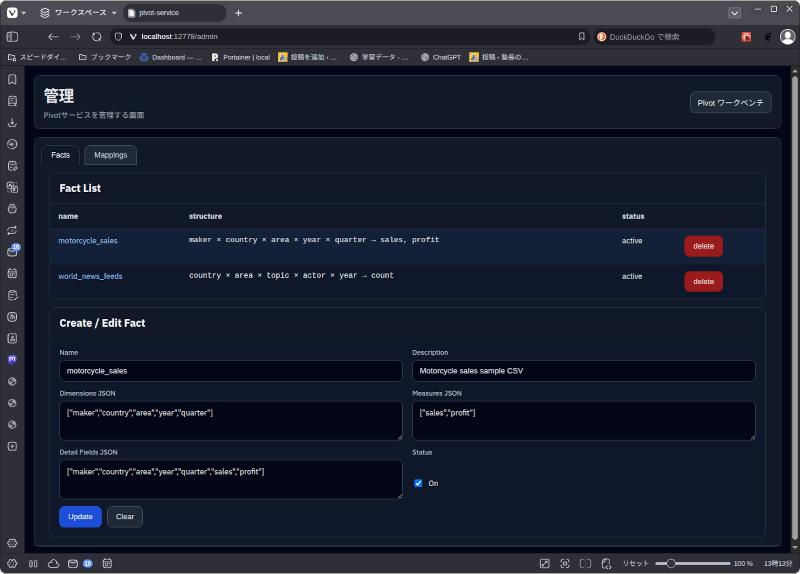
上のスクリーンショットがFact管理画面で、motorcycle_salesというFactを定義している様子。
maker、country、area、year, quaterという観測軸でsalesとprofitを観測するという定義になっています。
このFactにこんなデータを食わせてみました。
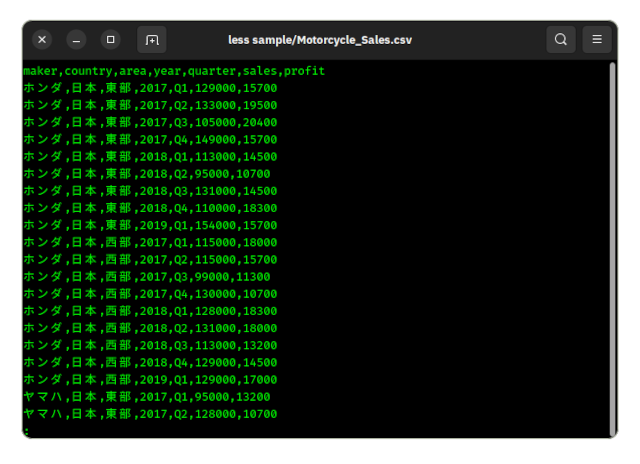
一般的にBIと呼ばれている分野のアプリケーションでよくやるタイプのデータ分析です。
Pivotサービス側のデータ投入口はすでに完成しているので、簡単なデータ投入プログラム(Ingester)を書いて、このデータをPivotサービスに投げます。
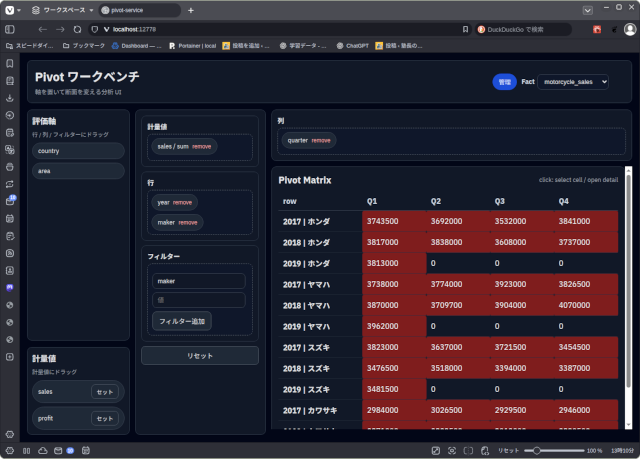
そうすると以下のように観測軸を変えながら、データを観測できる。
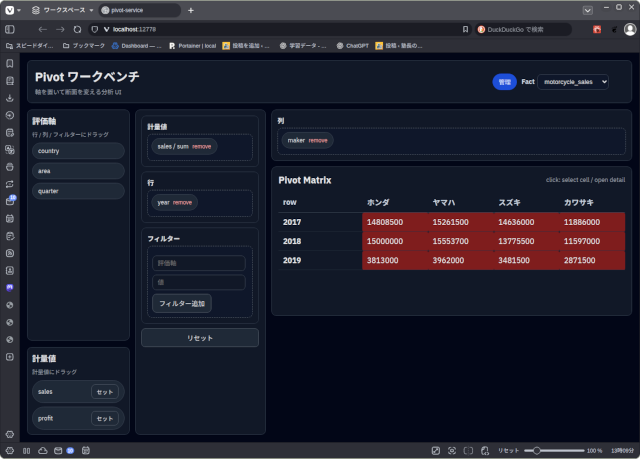
メーカーと年度で集計(2次元スライス)
メーカーと年度+四半期で集計(3次元スライス)
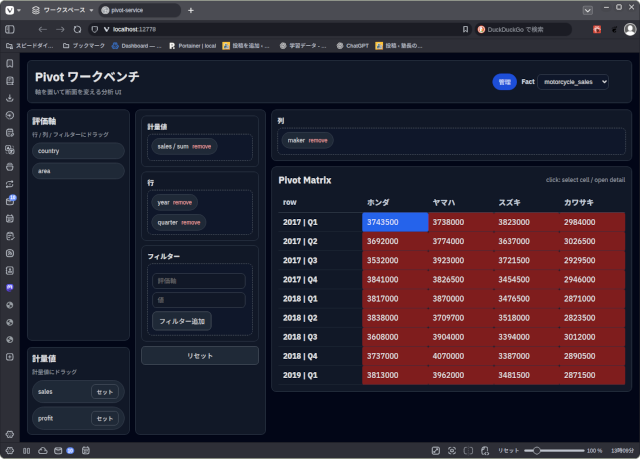
四半期と年度+メーカーで分析(3次元スライス)
通常のBIツールの場合は、ここからレポートを作成したりグラフを描画したり、ドリルダウンしたりします。
こういう使い方でも十分有用なツールではありますが、ZIKUUの場合は、あらゆるデータをPivotに投入して、こういう意味空間の断面をAIに探索させ、情報の束から意味を導き出します。
AI塾長と人が、同じ論文Factを探索しながら、意見交換する。
人の問いに対して、AI塾長が自動的にPivotを動かして意味を探索して、「Aの見方をすればこうだけど、Bの見方をすればこうだ」のような思考の補助をする。
出力のマトリクスは、ヒートマップにもなるので、例えば国際ニュースFactを見て、紛争関連ニュースは中東に集中している、ロシアとアメリカでニュースの扱いが多い、ミサイルに関するニュースが多い、みたいな温度を俯瞰したり、外れ値を検出するといった使い方ができる。
ZIKUUが作るのは、AIが答えを出すシステムではなくて、比較・要約・集計・パターン認識に優れるAIが一緒に考えて、人の判断を助けるシステムです。
ここまでに実現したことは、
データ収集→意味空間に記録→観測
です。
最終的に、
データ収集→意味抽出(LLM使用)→意味空間(Pivot)に記録&長期記憶空間(Qdrant)に記録→観測(人)&意味探索(AI塾長)
という形になって、完成です。
データは日々の活動記録、ブログ、エッセイ、ZIKUU基礎教科書、論文、ニュース、ラジオ放送の文字起こし、人工衛星データ、画像など、ZIKUU内外で発生するすべてです。
これは、AIの高性能化競争に引きずられないシステムです。
VRAM 12GB〜16GBのGPUで十分な性能が出せます。
巨大なコンテクストウィンドウも不要です。
資金に余裕があれば、性能を上げるために接続するLLMを切り替えればいいだけ。

「データの受け皿が完成する〜Pivotサービス」への1件のフィードバック