ZIKUUのシステムは文明バックアップ装置なので、外の世界と断絶しても、思考、判断、活動を続けられる必要があります。ZIKUUはクラウドサービスをあまり信用しておらず、なるべく依存せずに活動を続けられるように設計しています。
ですから、外のデータをすべて内部に取り込み、整理、構造化した上で、Pivotサービスの投げ込んで意味空間を形成することになります。
ここ言う外のデータとは、
- 国際ニュース
- 人工衛星観測データ
- ラジオ放送
- 論文
- ブログ
- Discord/Slack/Trello/Notionなど
- YouTube
- 出版物
などの、ZIKUU外のサービスが配信するデータです。
これらを取り込んで、内部の曖昧記憶(ベクターデータベース)と構造化記憶(Pivot)にすべて沈めて、それをPivot Reasoning EngineやAI塾長が覗きにいきます。
取り込んだデータは内部のGiteaリポジトリに原本として置きます。
ZIKUU Context Pipelineと名付けた、
外部情報→Giteaアーカイブ→ベクターデータベース/Pivot
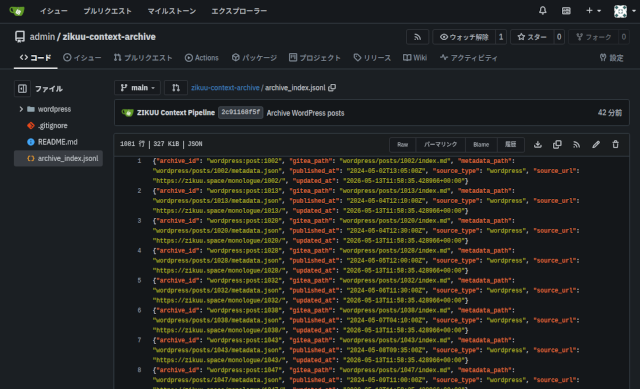
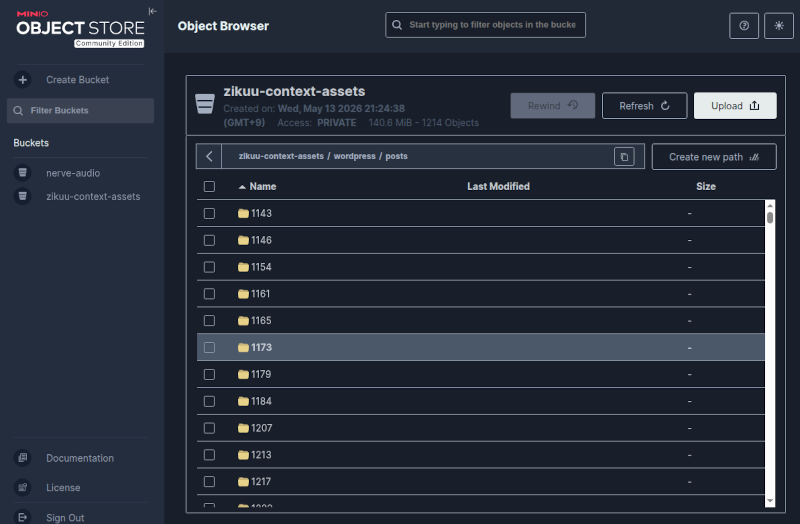
というパイプラインを情報源の数分実装することになりますが、今日は、WordPressブログのデータを取り込んで、Giteaリポジトリに保存、記事中の画像をMinIOに保存するまでの処理を書きました。
これがGiteaに取り込んだブログ投稿をMarkdown化したもの。
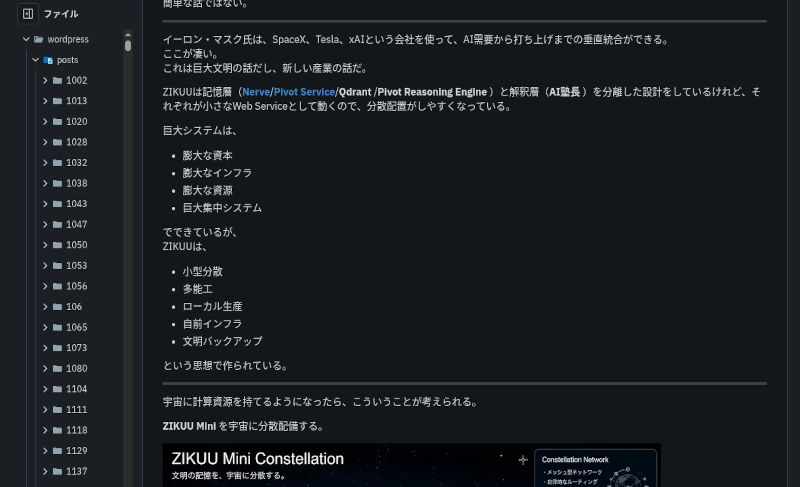
これがMinIOに保存された記事中の画像。

ブログ投稿はすでにQdrantベクターDBに沈めるパイプラインが走っているので、この後は、これらをPivot用のFactに構造化して、意味空間を作ることになります。

「各種データをPivotサービスに投げ込む準備」への1件のフィードバック