複数のLLM Runner を用途ごとに切り替えて使えるようにしたいと思い、LLM Brokerというサーバーの開発を始めました。
本番環境のサーバーは、いずれ省電力なミニPCにしようと思っていますが、Strix Point搭載ミニPCのようなdGPUが載っていないPCでLLMを走らせようと思うと、現時点ではllama.cpp一択です。
試しに、Xeon W-1250P (6C/12T)とRTX 3060を搭載したPCと、Core i5 13500 と RTX A4000を搭載したPCでllama.cppサーバーを動かして、gpt-oss-20b-Q4_K_M.ggufを使ってみたら、それぞれ80 tok/sec、100 tok/secという生成速度を得られました。
llama.cppなら、Strix Point搭載ミニPCでも実用的な速度が得られるかもしれない、ということもあって、これまで開発してきたアプリケーションと今後開発するアプリケーションで、用途に応じて、LLM Runnerを切り替えられるようにしておくのが良いという判断で、このLLM Brokerの開発に至ったわけです。
こんな風にプロフィールを定義します。
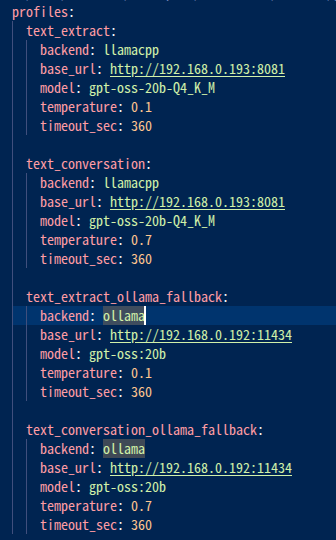
呼び出し側は、LLM Brokerに対して、プロフィール名でLLMを呼び出せるようになります。
要するに、アプリケーションとLLM Runnerを中継する薄い層を作ったわけです。
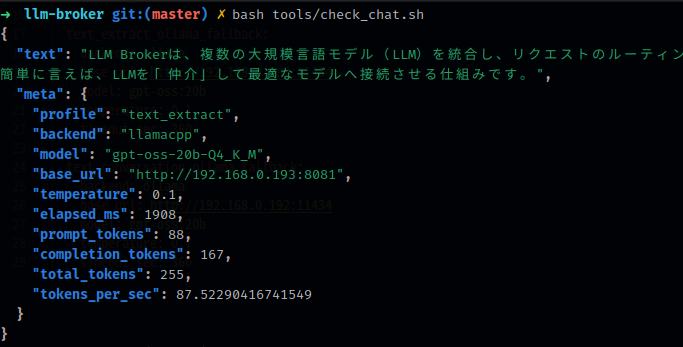
下のスクリーンショットは、テスト用のスクリプトで、2つのプロフィール、1つはllama.cppを使うもの、もう1つはOllamaを使うもの、でLLMを呼び出したときの結果です。
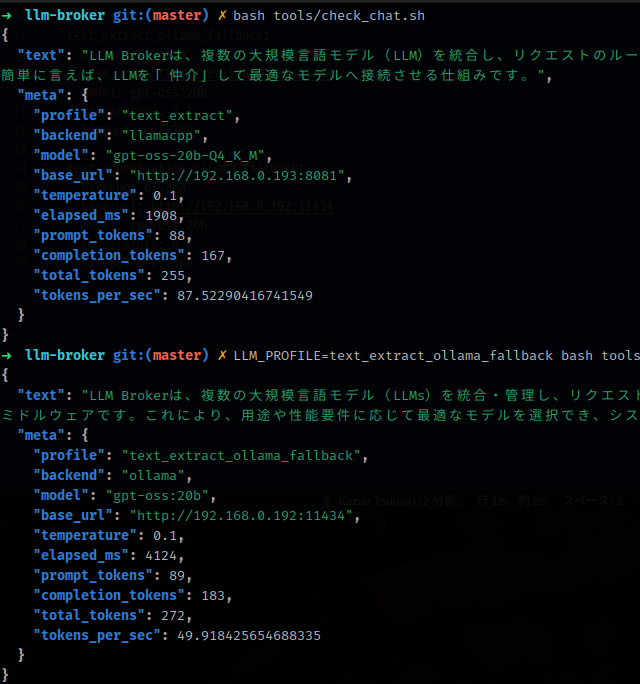
ちなみに1つめはXeon W-1250P + RTX 3060、2つめはCore i5 13400 + RTX 2000 Adaを搭載したPCで動いているLLM Runnerからの応答です。

「LLM Brokerを作る」への1件のフィードバック