CPSはContext Pipeline Serverの略です。長い名称なので、今後はCPSと書きます。
今日から、CPSの実装に入りました。
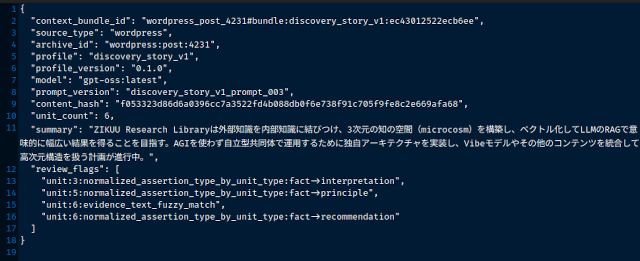
簡単なサーバーを書いて、そこでWordPressのブログ記事から文脈束を抽出するPoC (Proof of Concept = コンセプトの確認)をやりました。
これは、過去の投稿から文脈束を抽出したものの一部です。
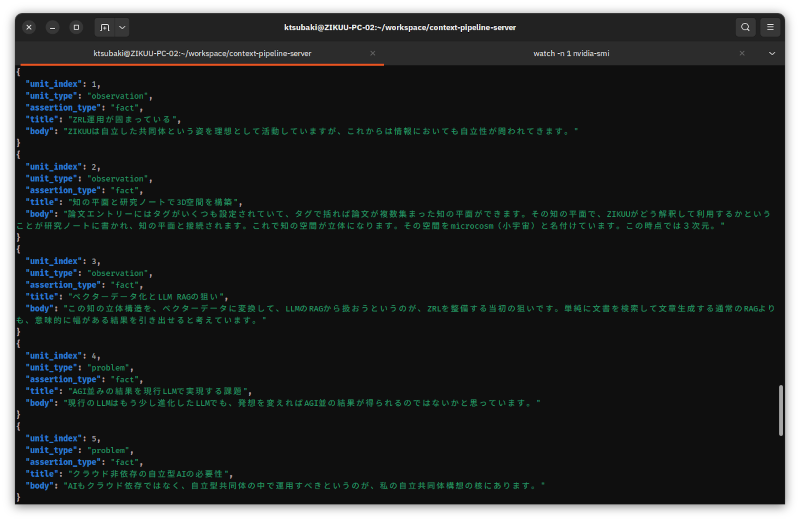
プロンプトの中に厳しい制約を入れ、温度0でローカルLLMを呼び出して文脈抽出をしています。
抽出対象:
- 観察
- 問題
- 試行
- 失敗
- 修正
- 発見
- 原理化
- 次の行動
重要な方針:
- 原文にないことを補わない
- 単なる要約にしない
- Fact化を急がない
- 人間が読んで違和感を確認できる粒度にする
- title、body、summary は必ず日本語で書く
- evidence_text は原文からそのまま抜粋する
- evidence_text を翻訳・要約・言い換えしてはいけない
- evidence_text には根拠となる原文の短い抜粋を入れる
- 判断や解釈は assertion_type=interpretation として扱う
- 原理化された内容は assertion_type=principle として扱う
- 不確かな内容は assertion_type=hypothesis として扱う
- 次にやるべきことは unit_type=next_action として扱う
- units は最大8件
- 同じ evidence_text を複数unitで使ってはいけない
- 同じ内容を observation / problem / trial / next_action に重複して出してはいけない
- JSONキー名は必ず英語の指定キーを使う
- unit_type は必ず unit_type キーに入れる
- assertion_type は必ず assertion_type キーに入れる
- title/body/evidence_text/source_span/confidence/review_flags/metadata のキー名を変更してはいけない
LLMに余計なこと、いい加減なことを言わせない。
LLMは、言葉の次の言葉を推論してつなげるようにできています。
ざっくり言うと、統計的に文章を組み立てる。
「それっぽいことを流暢に話す」のです。
それっぽいことを読んで、それっぽいことを回答するようなシステムでは使い物にならないので、ZIKUUでは、AIシステムが読む情報には、それっぽいものを入れたくありません。
ZIKUUのシステムは、
- 原文そのままのアーカイブ
- アーカイブから抽出した文脈束
- 文脈束を文脈に分解したFact
- Fact空間を探索するPivot
- Pivotを操作するPRE (Pivot Reasoning Engine)
- PREを操作するAI塾長と人
という多段構成の知識空間です。
それっぽいのは、最後のAI塾長の文章生成だけ。
最近はAIトップ企業の人たちも、知識はLLMの中ではなく、外側の仕組みに置く方が良い、といった主旨のことを言いはじめています。LLM性能競争には限界があるのでないかと考え始めているように見えます。
ZIKUUは、最初からそういうアーキテクチャーでLLMを扱っています。なので、LLM開発競争を遠目に眺めながら、知識空間を作るという面倒くさい作業を続けています。
余談ですが、文脈には因果が含まれます。
食糧危機が不安だから、小さな畑を始めた
のように。
しかしながら、人間は行為の理由を後付けすることがあります。
そうなると、因果がひっくり返る。
バイクを買った
という結果がある。因果としては欲しいだけ、みたいな。
でも、そこから、
経済的な理由や体力的な理由
を見つけて並べる。
本人は、あたかも、経済的な理由や体力的な理由で新しいバイクに買い替えたと思っている。
でも、因果を逆に辿ると、欲しいだけ、だったりする。
これを逆因果仮説という形で導き出す機能をPREに入れたら面白いなと思っています。

「CPS – 文脈束を抽出るするPoC」への1件のフィードバック