WordPress、Discord、論文、基礎教科書、ラジオ文字起こしなどのデータソースから取り込んだ各データを文脈束と読んでいます。そこには、いくつかの意味が束ねられているからです。
取り込んだデータをそのままPivotサービスに渡すわけにはいきません。
Pivotサービスが提供するのは、多次元意味空間=観測軸で切り取れる意味の塊ですから、文脈束から意味を抽出して、それぞれに観測軸を付与してPivotサービスに投入する必要があります。
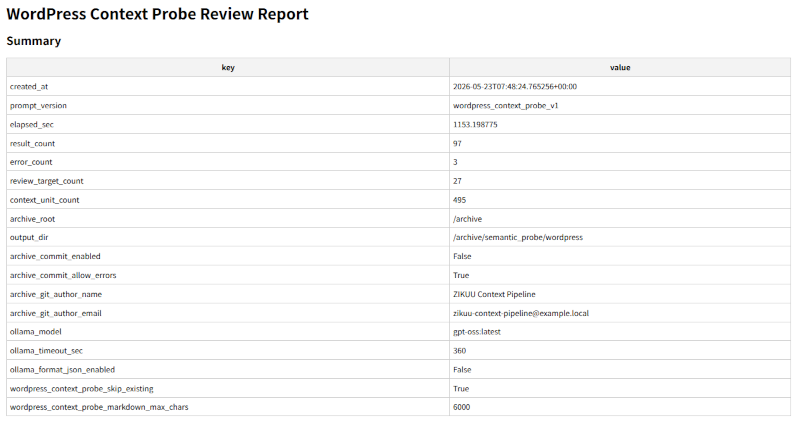
上のスクリーンショットは、context_probeというプログラムで、WordPressのブログ投稿から取得した文脈束から意味抽出を試み、その結果として出力されたレポートの概要です。
実際には、この下にエラーの原因の推定など、いくつかの評価指標が並びます。
意味をうまく抽出できたか、どのような観測軸を付与できたか、などの詳細が出力されます。
LLM推論の揺れ、サーバ負荷による遅延など、様々な要因で、意味抽出に失敗することがあり、それらをなるべく正確に把握するために、このプログラムを流します。
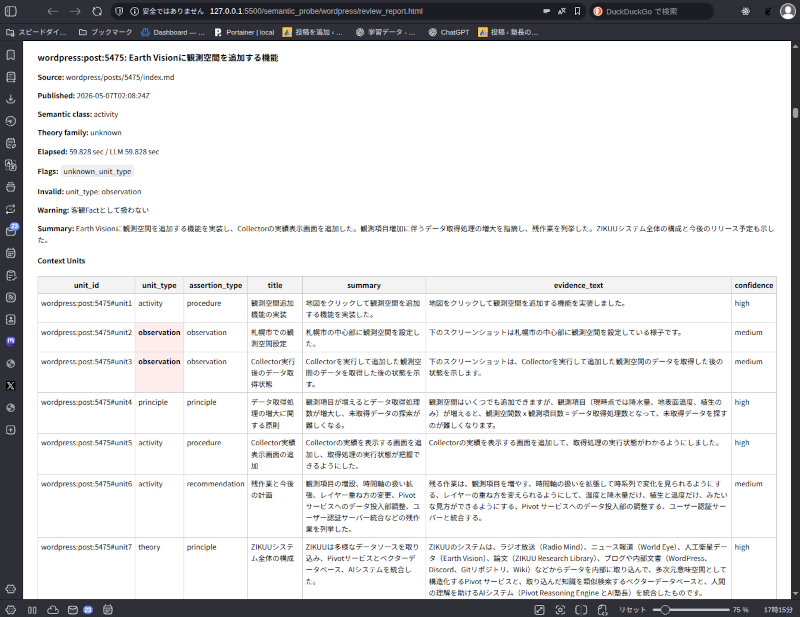
例えば、下のスクリーンショットは「Earth Visionに観測空間を追加する機能」というタイトルのブログ投稿から意味抽出を試みたときの結果です。
冒頭には、
- Semantic class: activity
- Theory family: unknown
- Flags: unknown_unit_type
- Invalid: unit_type.observation
- Warnings: 客観Factとして扱わない
などと出ています。
unit_typeのobservationが怪しい、このままでは客観的なFactとしてのPivot投入には問題あり。だいたいそんな風に読めます。
Context Unitsという表には、文脈束から抽出した意味単位ごとに、unit_type、assertion_type、confidenceなどの観測軸になるデータが並びます。
この表の1行が、Pivotサービスに投入するFactとして扱われます。
この投稿の例なら、7つのFactがPivotサービスに入る可能性があります。
これは人間が読むためのレポートですが、プログラム読むためのデータはこんな感じになっています。
{
"assertion_type": "procedure",
"claims": ["著者は地図をクリックして観測空間を追加する機能を実装した。"],
"concepts": ["観測空間", "Earth Vision"],
"confidence": "high",
"evidence_text": "地図をクリックして観測空間を追加する機能を実装しました。",
"observations": [],
"procedures": ["地図をクリックして観測空間を追加する"],
"recommendations": [],
"summary": "地図をクリックして観測空間を追加する機能を実装した。",
"title": "観測空間追加機能の実装",
"unit_id": "wordpress:post:5475#unit1",
"unit_type": "activity"
},
{
"assertion_type": "observation",
"claims": [],
"concepts": ["観測空間"],
"confidence": "medium",
"evidence_text": "下のスクリーンショットは札幌市の中心部に観測空間を設定している様子です。",
"observations": ["札幌市の中心部に観測空間を設定している"],
"procedures": [],
"recommendations": [],
"summary": "札幌市の中心部に観測空間を設定した。",
"title": "札幌市での観測空間設定",
"unit_id": "wordpress:post:5475#unit2",
"unit_type": "observation"
},
{
"assertion_type": "observation",
"claims": [],
"concepts": ["観測空間"],
"confidence": "medium",
"evidence_text": "下のスクリーンショットは、Collectorを実行して追加した観測空間のデータを取得した後の状態を示します。",
"observations": ["札幌市の中心部に観測空間を設定している"],
"procedures": [],
"recommendations": [],
"summary": "Collectorを実行して追加した観測空間のデータを取得した後の状態を示す。",
"title": "Collector実行後のデータ取得状態",
"unit_id": "wordpress:post:5475#unit3",
"unit_type": "observation"
}, 1 Unit が Fact 候補になります。
実は、このままFact化するのも難しいので、これを起点に構造変更をするプログラムを書くことになります。
ブログや論文などのように、自然言語で書かれた文章をまるごとLLMに投げて解釈させると、コンテクストが肥大化する、LLMが適当に文章を補ったり錯覚したりということが起きます。それはLLMのな使い方として望ましくない。
それらを防止するために、客観的に意味抽出をしたものをPivotの意味空間に置き、質の高い情報を読まることで、LLMがいい加減な解釈をしないように制御します。
ZIKUUでは、AIを、自然な文章を生成するおしゃべりマシンでも、人の代わりに考えてくれる便利マシンでもなく、人の思考や判断を拡張する伴走者と位置付けています。
いい加減な解釈が混ざった自然な文章などを生成されても嬉しくないわけです。
そのためには、LLMを動かす前段階が重要なのです。

「Context Pipeline〜文脈束から意味抽出」への1件のフィードバック