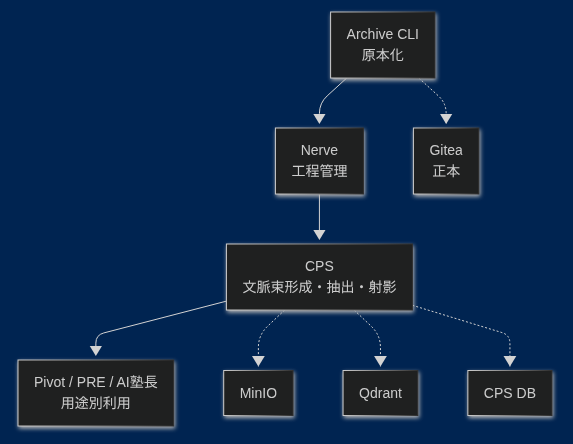
CPSの全体像
上の図は、CPS (Context Pipeline Server) 周辺(CPSとその後段)の責務を表した図です。
もう少し詳細なフローチャートにするとこういう感じ。
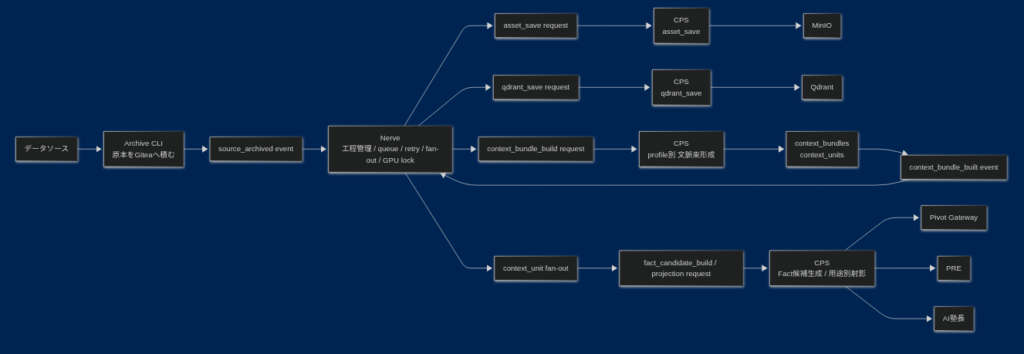
各データをCLIで読み込みGiteaに原本としてアーカイブし、Nerveにより1件ずつ、CPSにリクエストが飛んで、画像などのアセット保存・ベクターデータベースへの保存・文脈束の抽出を行い、最後にCPSがFact候補を生成してPivot Serviceのゲートウェイに送信する。PRE (Pivot Reasoning Engine)とAI塾長は、Pivotを入口にして、文脈束・原本・アセットを参照する。
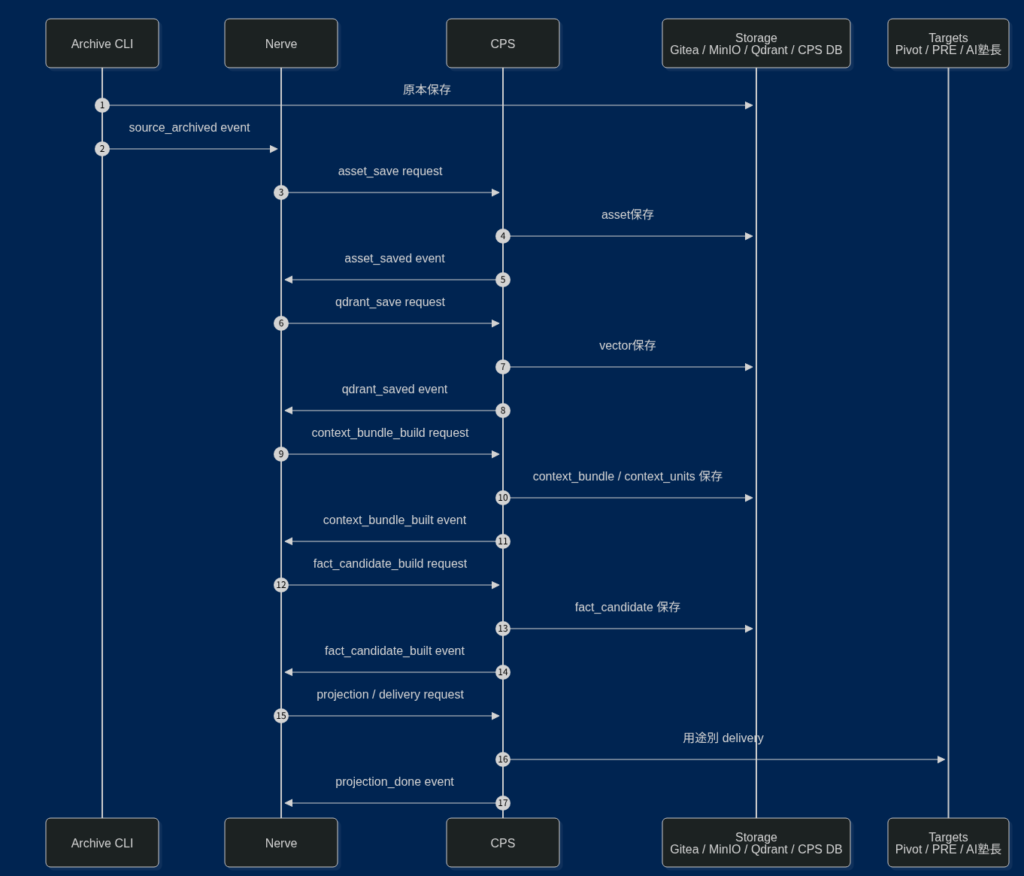
シーケンス図にするとこんな感じ。(簡略版)
ZIKUUシステムのコアは、ストレージです。LLM内に知識をなるべく持たせずに、知識空間をLLMの外に置く構造だから。
文脈束抽出のためのプロフィール
CPSは、対象データに応じて、文脈束を抽出するためのプロフィールを持ちます。ブログの活動記録ならこれ、エッセイならこれ、小説ならこれ、教科書ならこれ、といったプロフィールが用意され、それぞれに適した文脈抽出をする。さらに、一つのデータに対して複数のプロフィールを持つことによって、プロフィールの切り替えで、同じデータでも違う文脈が抽出できる。
下の表は、2種類のプロフィールで同じブログの文章から文脈束を抽出した結果です。

これは複数の視点で、共同体の記憶を辿り、そこから立ち上がる意味をLLMに読ませるためのアイデアです。もちろんPivot Workbenchを操作して、人がこの文脈を読むこともできます。
データの発生源は、外部の情報ソースと内部のブログとDiscordだけ。
入力の手間は、このシステムが動いても増えない。
知識を参照する場所は、AI塾長だけで、面倒くさい知識の整理はすべてバックグランドで自動的に行われる。
行き詰まったらAI塾長に相談して一緒に考える。
そして、ZIKUU(およびこのシステムを導入した共同体)は、日常の作る・学ぶに専念できる。
ZIKUUシステムは、意味や文脈を計算するコンピューターシステムになりつつあります。

「CPS – 全体像と文脈束を抽出するプロフィール」への1件のフィードバック