Discordの観測装置
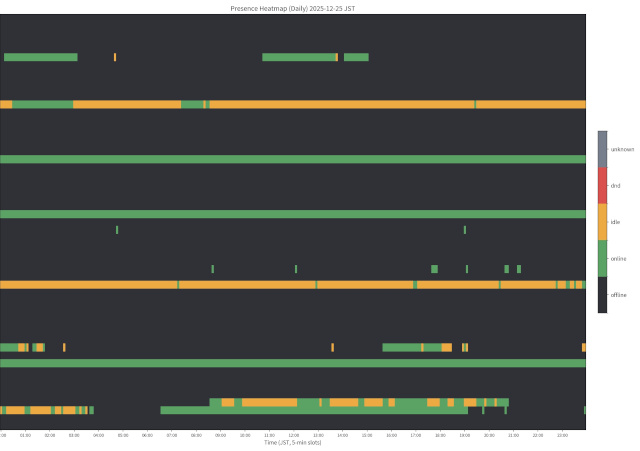
上のスクリーンショットは、Discordサーバー内のオンライン状況をヒートマップにしたものです。こういうボットを簡単に作れてしまうDiscordはとても扱いやすい。 ZIKUUは実際に手を動かす作業が主なので、Disco … 続きを読む
上のスクリーンショットは、Discordサーバー内のオンライン状況をヒートマップにしたものです。こういうボットを簡単に作れてしまうDiscordはとても扱いやすい。 ZIKUUは実際に手を動かす作業が主なので、Disco … 続きを読む
サーバーにGPUが載ったこともあり、やっとAI塾長の開発を始められます。 ZIKUUの完成形は、 の4つの層が揃ったときに見えてきます。それがZIKUU v1.0。別名、文明のバックアップ装置v1.0です。 1から3はす … 続きを読む
前回、複数チャンネルに対応してDiscord Ingesterを作り、Discord投稿を自動的に取り込む準備ができました。 AIは形式知(言葉にできる、コピーできる)については、人間を凌駕している部分が多いので、そこを … 続きを読む
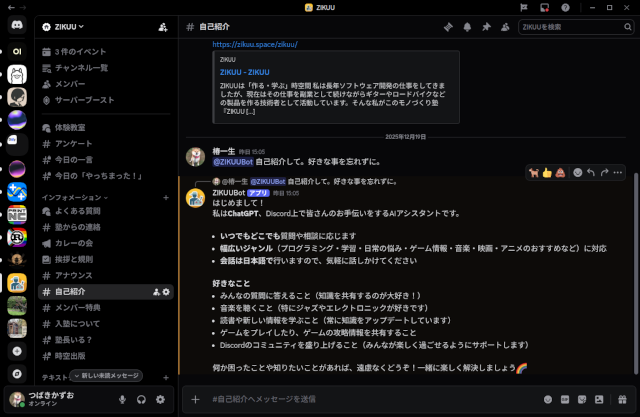
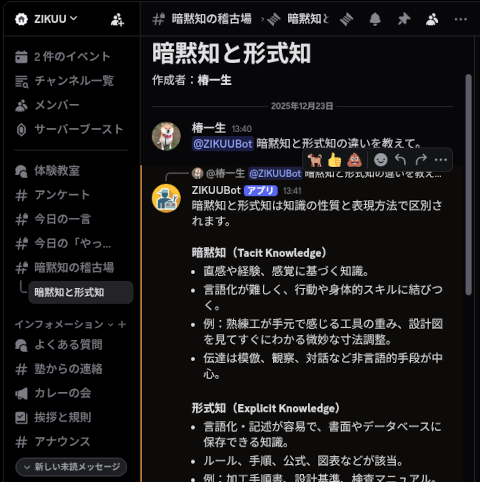
AIサーバーが立ち上がったので、Discord用のサービス「AIチャットボット」と「AIコーチ」をgpt-ossを仕様するように調整しました。 上のスクリーンショットがチャットボットの方です。これは単発で、ユーザーのメッ … 続きを読む

昨日、正式にZIKUUのサーバーでGPU(RTX 2000 ada 16GB)を使いLLM(gpt-oss:20b)を常時稼働させました。それにより、Discordで動いているAIチャットボットとAIコーチ(メンバーの作 … 続きを読む
モノづくり塾では、朝一番に便所掃除をします。素手でやります。 塾生が作業しているときは、床に落ちた木屑を静かに掃いて整えます。 これには三つの理由があります。 1. 掃除をすると心が整う まず、自分のためになります。 2 … 続きを読む
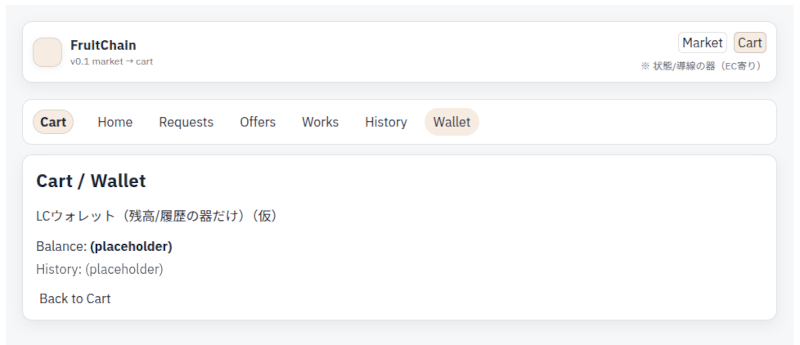
まだ、ビジネスアプリっぽいですが、画面遷移が明確になったので、今日はここまで。これでフロントエンドの全機能が視覚化できました。 最終的には、Amazonやヤフオクのような、ECっぽいデザインにします。 FruitChai … 続きを読む
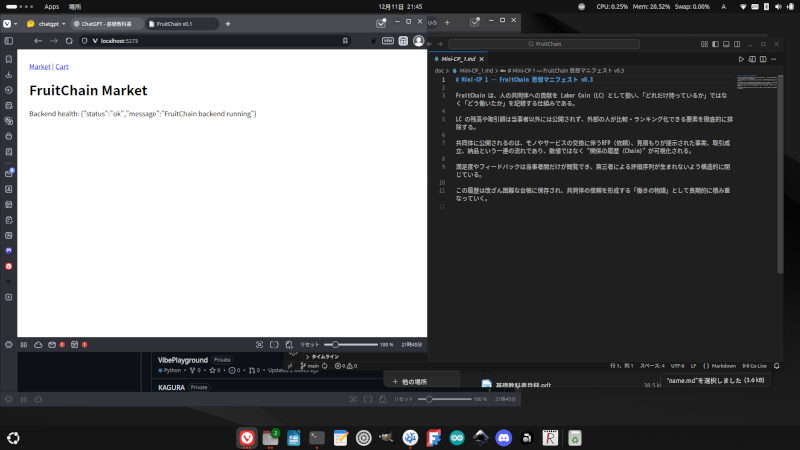
以前、モックアップを開発した話を書きましたが、プロトタイプの開発を開始しました。 FruitChainが生まれる社会背景については、最新の論文に詳しく書いているので、そちらも参考にしてください。すでに評価経済という文脈で … 続きを読む

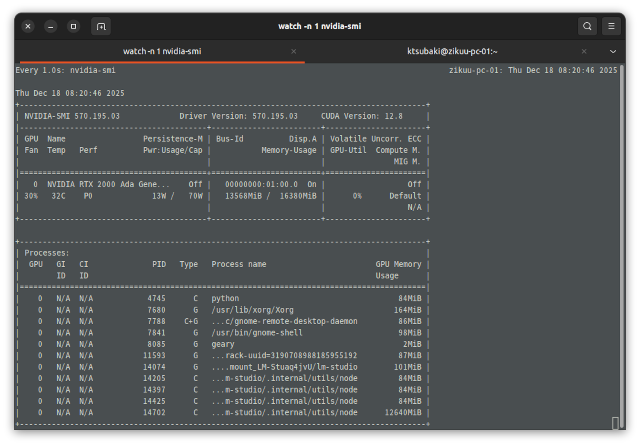
塾のサーバーに載せるGPUが届きました。NVIDIA RTX 2000 adaという製品で16GBのVRAMを搭載しています。この製品の美点は消費電力が少ないこと、補助電源が不要なこと、小さいこと、VRAMが大きいこと。 … 続きを読む