今日は朝早くからZIKUU Context PipelineのDiscord用パイプラインの開発をしています。
このプロジェクトは外界(外部のサービスやサイト)の情報を、すべて内部に引き込んで構造化するプロジェクトです。それらは、ベクターデータベース(うろ覚えの記憶と呼んでいる)とPivotサービス(多次元意味空間と呼んでいる)に保存され、人とAIが記憶を辿りながら解釈・解析・パターン抽出などを行います。
午前中のうちに、Discordチャンネル→Giteaへのアーカイブ→添付ファイルのMinIOへの保存→会話単位にベクターデータ化してQdrantに保存、までの処理を書きました。
これがZIKUUのDiscordに登録した、ZIKUU Context Pipeline用のボット。
複数チャネルに対応しており、ZIKUU内の日々の活動や知見が投稿されているチャンネルからすべてのメッセージを取り込みます。
Giteaに取り込んだメッセージのアーカイブ。
人間が読むためのMarkdownファイルと、プログラムが読むためのJSONファイルが作られます。
メッセージ中の添付画像は、MinIOに保存されます。
これが保存された画像。
このブログでは、ソフトウェア開発の記事が多くなっていますが、ZIKUUの活動の主体は飽くまでもモノづくりの方ですから、ここにはこういう作業中の画像がたくさん蓄積されます。
ZIKUUでは、ITもAIも木工旋盤も横並びで、すべてが関連付けられています。

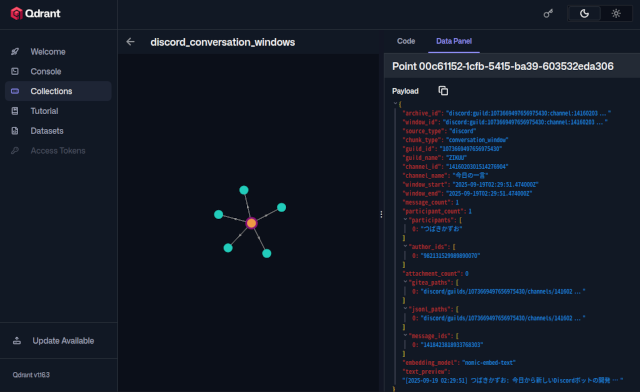
そして、Discordメッセージを会話単位でQdrantベクターデータベースに保存します。
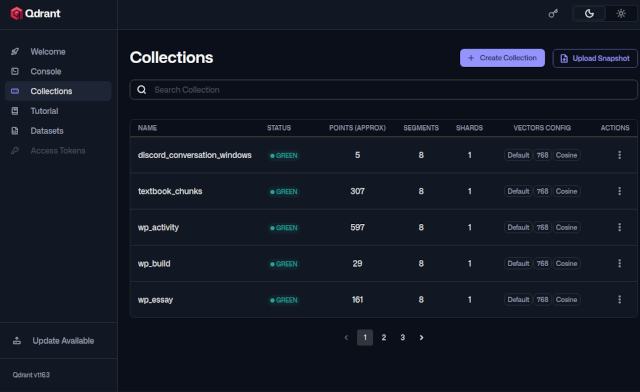
類似検索に使われるベクターデータが蓄積されます。
これは、意味的にけっこういい加減なので、うろ覚えの記憶と呼んでいます。
通常のRAG(Retrieval Augmented Generation)というテクニックでは、結構、いい加減な文章生成しがちですが、ZIKUUの場合は、Pivot Reasoning EngineがPivotサービスを探索してから、必要に応じてベクターデータベースを検索し、必要に応じてソースデータや画像を読みに行くようにします。
Pivotは、多次元意味空間を操作して、その断面を切り出し、あらかじめ意味を絞って、小さく・確定的に意味を把握するので、LLMがいい加減な文章生成をするのを抑制し、大きなVRAMを必要とせずに良い結果を導きます。

「Context Pipeline〜Discordメッセージをベクターデータベースへ」への1件のフィードバック