
ここまでで、WordPressブログ(活動記録とエッセイ)、Discordメッセージ(活動ログと社会観察)、ZIKUU基礎教科書フル版、ZRL (ZIKUU Research Library 論文アーカイブ)、ラジオ文字起こしの文脈束の抽出プログラムができて、今度は小説からの文脈抽出です。
上のスクリーンショットは小説『酔いどれ塾 ―ハットの中の奇跡―』の冒頭部分。
それから文脈束を抽出したのがこれです。
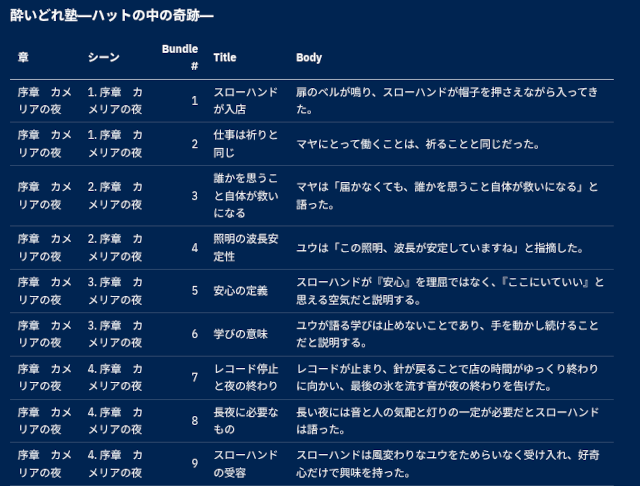
思いの外、小説の文脈抽出は面白い。
文脈抽出にはLLMを使いますが、LLMが話を作らないように注意しています。
そうしないと、本来の文脈がデタラメになりかねません。
これは、何度もプロンプトを作り直してテストを繰り返す泥臭い作業です。
いずれ、文脈の計算(合成、差分、掛け合わせなど)ができるシステムを作ろうと思っています。
それができると、酔いどれ塾の文脈と全く別の文脈を合成することで、新たな文脈を生み出せるはずだと思っています。
その合成した文脈を与えて、生成AIに小説を書かせると、描かれているシーンや人物は違うのに、どこかZIKUUっぽい小説になる、みたいなことになるかもしれません。
残るは、運用メモや開発メモのような内部文書から文脈抽出を試みます。

「CPS – 小説の文脈束を抽出する」への1件のフィードバック