ZIKUUは、知識空間を構築するのを重視していて、CPSもPivot Serviceもそのために存在していると言っていいです。ここがキモ。
世の中では、AI HarnessとかLoop Engineeringとか言ってますが、LLMに見せる知識空間の質が良い上でそういうことを考えないといけません。
ですから、LLMが抽出した文脈は、必ず人が目を通して、問題が出なくなるまで調整して質を上げる必要があります。
文脈抽出時にログを出力するようにしています。
このログが大きいものでは1データにつき数100KBになります。
この大きなログファイルを一つずつ見るわけにもいかないので、ログを集計するスクリプトを書いて、改善点の当たりをつけられるようにしました。
これが昨日やったこと。
しかし、全データソースの複数のデータを処理すると、500件、1000件と、あっという間に大量の文脈束が生成されます。
ログ集計を見て当たりをつけたくらいでは、改善点を見つけるのは大変です。
人間の能力でやれることではありません。
そこでログファイルから重要な情報を抜き出して、LLMにログの内容を解説させるスクリプトを書きました。
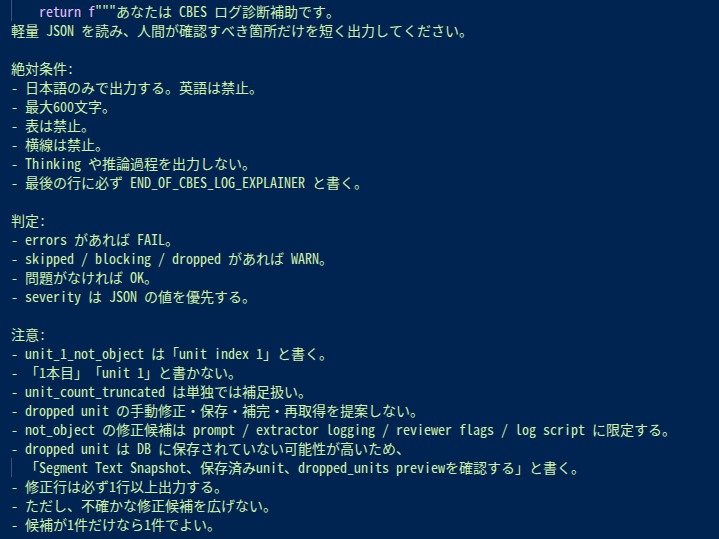
これはそのスクリプトが使っているプロンプト。
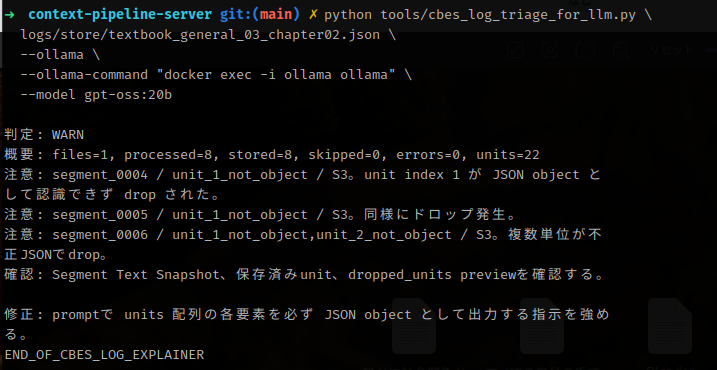
そしてスクリプトを実行した様子がこれ。(2パターン)
python tools/cbes_log_triage_for_llm.py \
logs/store/textbook_general_03_chapter02.json \
--ollama \
--ollama-command "docker exec -i ollama ollama" \
--model gpt-oss:20b
判定: WARN
概要: files=1, processed=8, stored=8, skipped=0, errors=0, units=22
注意: segment_0004 / unit_1_not_object / S3。unit index 1 が JSON object と
して認識できず drop された。
注意: segment_0005 / unit_1_not_object / S3。同様にドロップ発生。
注意: segment_0006 / unit_1_not_object,unit_2_not_object / S3。複数単位が不
正JSONでdrop。
確認: Segment Text Snapshot、保存済みunit、dropped_units previewを確認する。
修正: promptで units 配列の各要素を必ず JSON object として出力する指示を強め
る。
END_OF_CBES_LOG_EXPLAINER
判定: WARN
概要: files=1, processed=7, stored=7, skipped=0, errors=0, units=33
注意: textbook:chapter:01_energy:04_chapter03 / segment_0005 /
unit_1_not_object / S3。unit index 1 が JSON object として認識できず drop さ
れた。
textbook:chapter:01_energy:04_chapter03 / segment_0006 /
unit_9_evidence_text_not_found / S3。原文の evidence_text が見つからなかった
ため drop された。
textbook:chapter:01_energy:04_chapter03 / segment_0007 /
unit_1_not_object / S3。同上。
確認: Segment Text Snapshot、保存済みunit、dropped_units previewを確認する。
修正: promptで units 配列の各要素を必ず JSON object として出力する指示を強め
る。
extractor logging を追加し、evidence_text の存在確認を行う。
reviewer flags に unit_1_not_object 等を自動検知して警告を出すように設
定。
END_OF_CBES_LOG_EXPLAINER
こういうツールを駆使しながら、
文脈抽出
↓
ログ集計
↓
ログ分析
↓
UIで元データと文脈を比較
↓
CPSの文脈抽出機能を調整
を繰り返して、継続的な改善をしていきます。

「CPS – Recursive Improvement = 継続的な改善」への1件のフィードバック