ZIKUU Context Pipelineの開発をしばらくやってきましたが、実際に動かしてみると運用に耐えられないことが明確になりました。
ZIKUUのような小さな組織では、GPUは貴重な資源。その資源を様々なプログラムが共有して取り合いになります。幸い、今後、開発する対話系のAIアプリとは違い、ここまでに開発してきたプログラムは、深夜のバックグラウンド処理ばかりなので、即時応答性は犠牲にしても構わない。
こういう場合に使われることを想定したシステムがすでにあるので、それを利用する形でContext Pipelineの機能を作り変えます。ここで利用するのがNerve。
Nerveは、あらゆるものがイベントとしてキューに投げ込まれ、ハンドラーがキューから1つずつイベントを取り出して処理する仕組みなので、バックグラウンドで大量のLLM推論などの時間のかかる処理があっても、処理に詰まらない。
今日は、すでに本番環境で動いているNerveを開発環境で独立して動かせるように改修しました。細かなところでしたが、本番環境前提で書かれた設定ファイルやプログラムがあったので修正が必要でした。
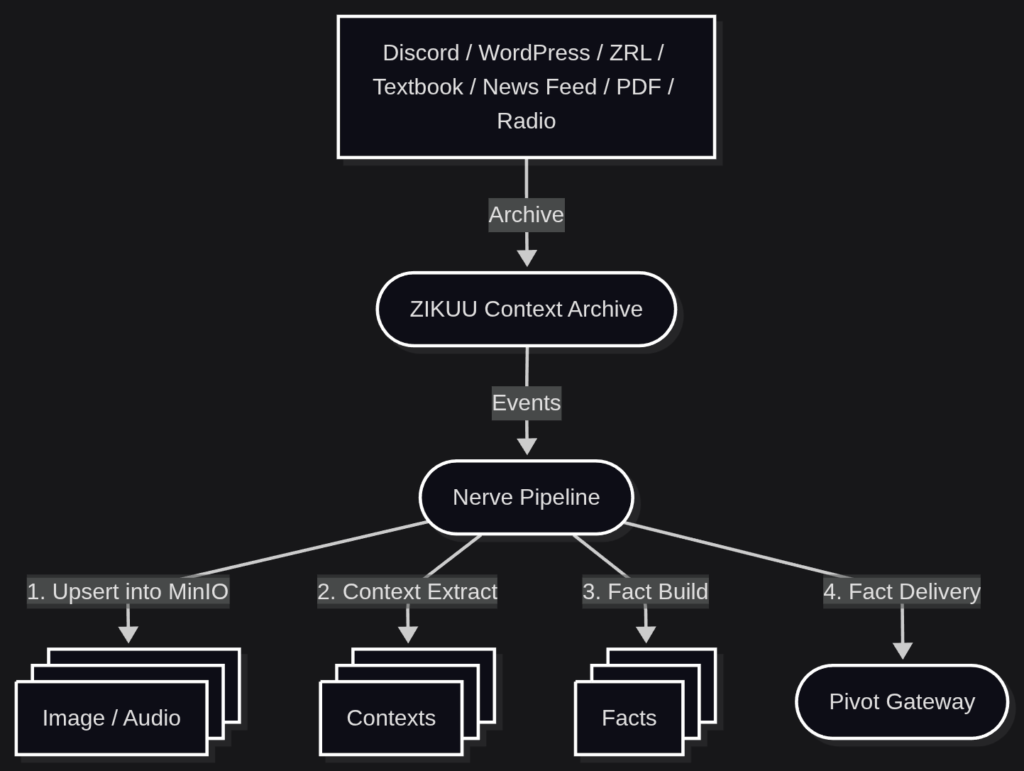
前回までに開発をしてきたZIKUU Context Pipelineはすべての機能がバッチ処理として書かれていましたが、Nerveイベントに対応するために、ドキュメント単位でイベントをキューに投げ込む仕様に大幅に修正します。それにともない、バッチ処理プログラムだったものを、常時起動のサーバーに変更して、NerveとContext Pipeline Serverの間で、逐次通信をしながら、データのアーカイブ、画像などのアセットの保存、Pivot用Factの生成とPivot Gatewayへの投入を一つずつ実行するようにします。
全体図
シーケンス
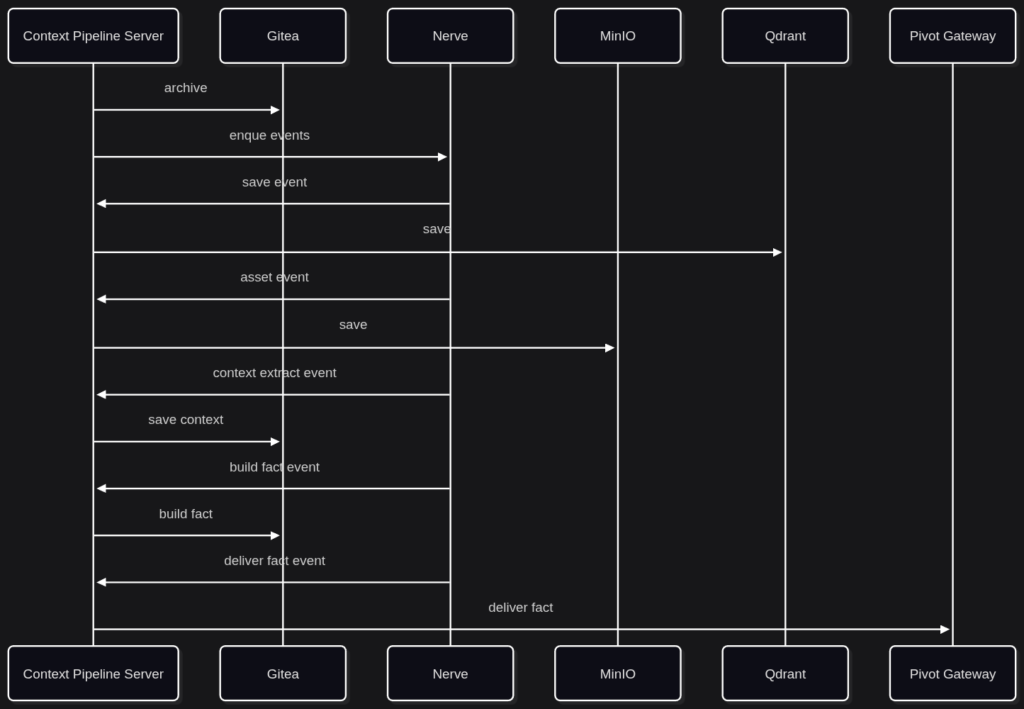
この開発は、Nerve Pipelineの開発、Context Pipeline Serverの開発、Gitea、MinIO、Qdrant、認証サーバー連携など、複数の領域にまたがる作業になるので、認知負荷の増大に対応しながら進めます。
たぶん、ZIKUUのシステムの開発を始めてから最も脳への負荷が高い作業になります。
これが終われば、Pivot Reasoning EngineとAI塾長を開発してZIKUU v1.0は完成ですが、今回の開発が山場になりそう。

「Context Pipeline Serverを開発する準備」への1件のフィードバック