ZIKUU Research Library (ZRL)は、Discordボット/Gitea/ローカルLLM/Nerve/Qdrantが連携するシステムで、DiscordでarXivの論文検索リクエストを送信すると、ボットがarXivの論文を検索して、構造化してGiteaに保存し、Git ActionsがNerveにイベントを送信、最終的にQdrantに論文を保存するというワークフローを実行するシステムです。
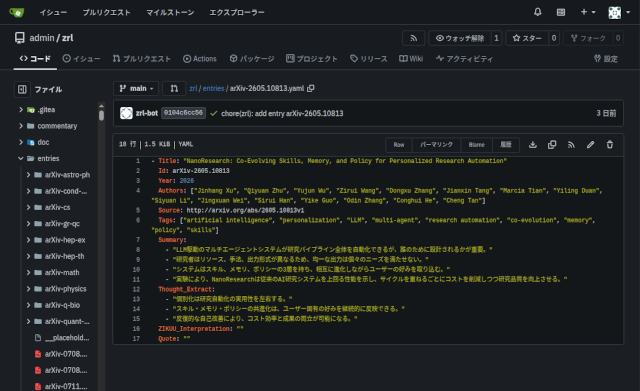
これが自動整形された論文エントリ。
これが自動要約された論文。
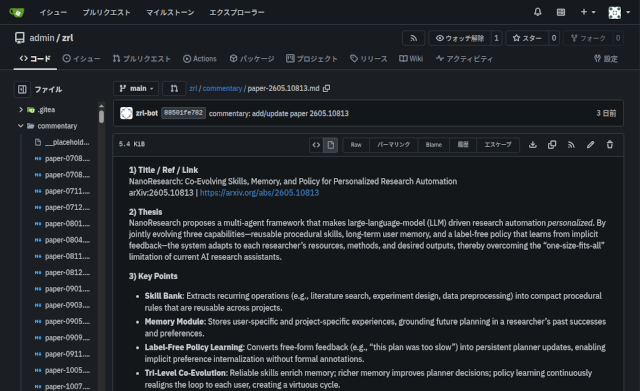
どちらも、タグの抽出、テーマの抽出、要旨の抽出などをローカルLLM(Ollama + gpt-oss:20b)がやっています。
この時点で構造化された論文情報になっていますが、これは飽くまでも人が見るもの。
今日はこのZRLの外側に、ZRLのリポジトリを読んで、PivotサービスにFactを投入するパイプラインを作りました。ここでさらに意味を加えた構造化を行いAIが見る情報になります。
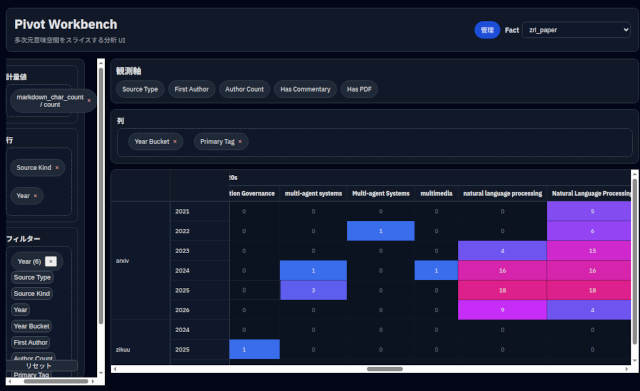
Pivotサービスに入ったFactをPivot Workbenchで表示したのが冒頭のスクリーンショットです。
ここまでで、World Eye由来の国際ニュース、Earth Vision由来の地球観測データ、arXiv由来の論文、WordPress由来の活動記録とエッセイ、Discord由来の活動ログがPivotに入ったことになります。
残るは、ZIKUU基礎教科書由来の教養や論理とRadio Mind由来のラジオニュースのためのパイプラインの開発です。
要するに、
- 国際ニュース
- 国内ニュース
- 地球観測データ
- 活動記録
- エッセイ(思想)
- 教科書(教養と論理)
といった、コミュニティー内外の情報を多次元意味空間に蓄積されることになります。
ここまでZIKUU v1.0で想定している知識化対象ですが、活動記録・思想や哲学・教養や論理は、それぞれのコミュニティー独自のものに差し替えれば、コミュニティー特有の知識化ができます。これは飽くまでも知識化の枠組みです。
ZIKUUの発想は、いい加減なおしゃべり機械であるLLMに委ねずに、LLMが読む知識環境を整えます。結果的に、LLMの選択肢が増え、計算資源の節約を狙えます。

「Context Pipeline〜ZIKUU Research LibraryをPivotサービスに投入」への2件のフィードバック