
RSSフィードから直接Pivot Serviceに投入していた国際ニュースでしたが、これもCPSを通して文脈抽出後にPivot Serviceに投入することにしました。
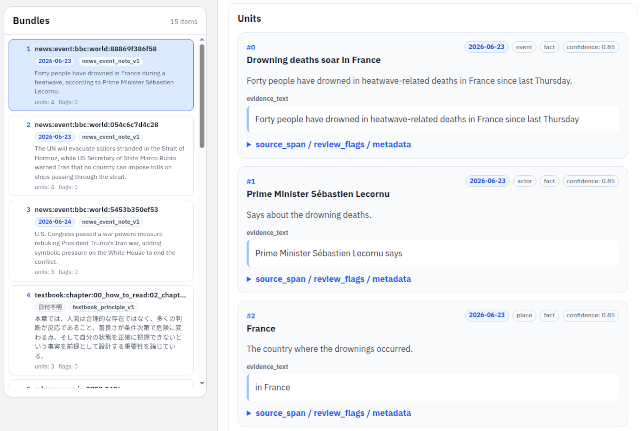
他のデータはGiteaのリポジトリに原本を保存した上で、CBES (Context Bundle Extraction Strategy) を通していますが、国際ニュースに関しては、データの増え方が尋常ではないので、原本は捨てることにします。
どのみちPivot Serviceには記事の本文が保存されるので、あえて原本を保存する必要がないという判断です。
今日までに、
- ZRL (ZIKUU Research Library)
- ZDL (ZIKUU Document Library)
- WordPress投稿
- 基礎教科書
のCBESを実装しました。
残るは、
- ラジオ文字起こし
- Discord投稿
- 小説
です。そこまで行くと、CBESの文脈抽出パイプラインは完成。
その次に、それらからFactを生成して、Pivot Serviceに投入する機能を実装して完成に向かいます。
これが完成すると、ZIKUUが使用する内外の知識のほぼすべてから文脈抽出と意味空間構築ができることになります。
国際ニュースの対応と並行して、大きな変更をしました。
それは
すべての文脈束に文脈発生日時を入れるです。
昨日、ぼんやりと文脈束を眺めていて気づいたのが、
文脈を時系列に並べると、思考、判断、試作などの流れがはっきりつかめることでした。
これができると、思考・判断・行動の記憶を未来に継承できる。
このようなことをRAGでやるには、膨大な量のテキストをLLMに読ませてやらないといけませんが、文脈束を選択してLLMに渡すなら軽いし、LLMがいい加減な根拠で作り話を作るのを避けられます。

「CPS – 国際ニュースからも文脈抽出」への1件のフィードバック