CBES (Context Bundle Extraction Strategy)という構造をCPSに入れました。
これにより、
CPS (Context Pipeline Server) は、データソースに応じた CBES (Context Bundle Extraction Strategy) を動的に読み込み、アーカイブ読み込み、データのセグメント分割、文脈の抽出、文脈の正規化、Factの生成とPivotサービスへの送信を行うパイプラインサーバー
と表現することになります。
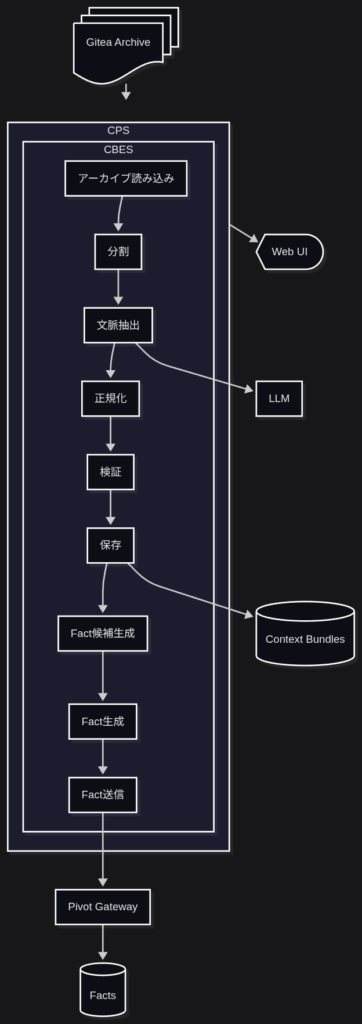
これは、文脈抽出に関する一連の処理を、小さな責務に分けて、順次実行する構造で、それらを抽象化し、汎用的な機能は具象化することで、各責務ごとにコンポーネントの差し替えを可能にするための対応です。
実際の運用では、
何らかのプログラムがデータソースからデータを収集してテキストはGiteaに画像はMinIOにアーカイブする
↓
Nerveにデータを一件ずつイベントとして送信する
↓
Nerve PipelineがCPSのAPIを呼び出す
↓
CPSはCBESを組み立てて文脈束の抽出からFact生成とPivot Gatewayへの送信までをやる
という形になります。
途中にQdrantへの、全文保存、文脈保存を挟むことになりますが、だいたいこんな流れです。
このZIKUUのシステムは、塾生やスタッフから見るとAI塾長アプリですが、AI塾長が見るデータを作るために、様々なプログラムが裏で動作します。Dockerコンテナの数にすると30個くらい。
中核は、イベント配送をするNerve、文脈を処理するCPS、意味空間を扱うPivot Service、原本・文脈・意味空間を探索するPRE (Pivot Reasoning Engine)など。
開発側の感覚では、主役はAI塾長じゃなくて、こちらの中核システムの方です。
AI塾長を作ろうと思った時点では、
RAGとファインチューニング
がテーマだったのが、
データ収集をしているうちに、それでは駄目だということに気づき、
Pivot Serviceを作って意味空間の断面を見る
という考え方を導入しました。
ところが、前々から、
意味は文脈から立ち上がる
という考えを持っていたので、
文脈抽出こそ重要だ
という考えに至り、CPSを開発することになりました。
今、ちょうどその本丸の開発をしていることになります。
これが終わって、PRE = 意味空間を探索するエンジン、それに繋ぐAI塾長、そしてシステム全体を説明できるRepository ExplorerまでできたらZIKUU v1.0完成です。
その後は、日々の活動の中でAI塾長を使いながら改善を繰り返す、コアシステムを研究装置として使って、新たなアプリケーションを生み出す、という流れになります。
つまり、終わりがない。

「CPS – Context Bundle Extraction Strategy」への1件のフィードバック