すべてのデータソースから文脈抽出ができるようになったので、抽出内容を検査する仕組みを入れました。
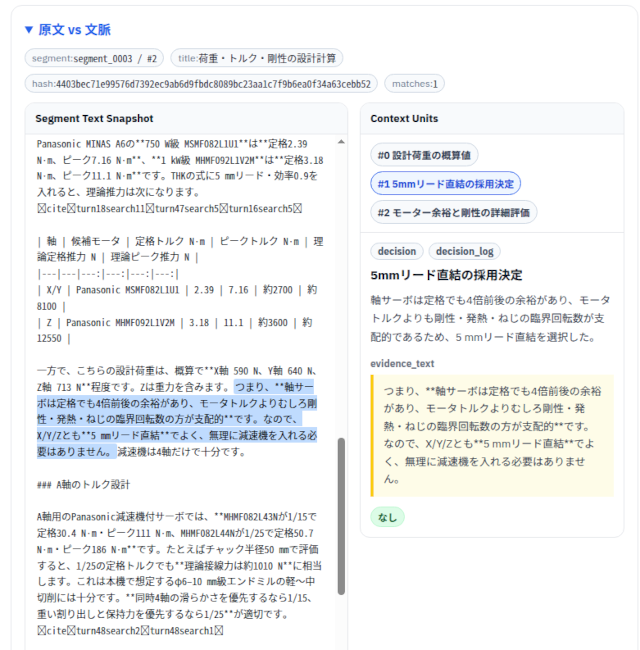
原文と文脈束を左右に表示して比較できるUIです。
文脈を扱う上で、次のことが重要です。
- 抽出した文脈が本当に文脈として有効である
- 話を盛っていない
- 欠落がない
LLM統計的に単語や文字をつなげる仕組みなので、素性としてはいい加減です。
そこにいい加減な文脈を読ませてはいけない。
なので抽出した文脈の品質が重要になるわけです。
人間が検査しなければなりませんが、それは品質が落ち着いてくるまでの苦労です。
すべてのデータソースから、5から10のデータを処理するスクリプトを作ったので、それを流して抽出された文脈を検査する。
問題があれば、抽出機を調整する。
これを何度も繰り返します。
スクリプトの実行に約1時間かかるので、一日に何度もやれませんが、数日頑張ればなんとかなるでしょう。
幸いスクリプトはバックグラウンド処理なので、処理をしている間に他のことがやれます。

「CPS – Evidence Review画面を追加」への1件のフィードバック